
本文主要针对Python中数据类型和数据处理方式的介绍,包括mat、list、ndarray等。
1. mat
1.1. MATLAB保存mat文件
如下例子所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
clear
clc
maindir = 'Results';
subdir = dir( maindir );
j = 1;
for ii = 1 : length( subdir )
if( isequal( subdir( ii ).name, '.' )||...
isequal( subdir( ii ).name, '..')||...
~subdir( ii ).isdir) % skip if not dir
continue;
end
matfile = fullfile( maindir, subdir( ii ).name, 'Result.mat' );
condition = split(subdir( ii ).name, '_');
load(matfile)
dataCell{j,1} = condition(2);
dataCell{j,2} = condition(3);
dataCell{j,3} = DesireStatus;
dataCell{j,4} = DesireControl;
j = j + 1;
end
save('MixResults.mat','dataCell');
最终保存的文件形式如图所示
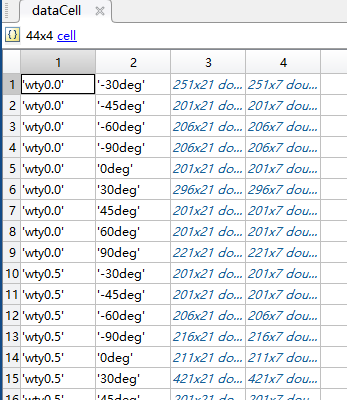
1.2. Python读取mat文件
1
2
3
4
5
import scipy.io as sio
import numpy as np
load_path = 'MixResults.mat'
load_data = sio.loadmat(load_path)
此处得到的 load_data 是如下形式的值
1
2
3
4
{'__globals__': [],
'__header__': b'MATLAB 5.0 MAT-file,...00:47 2020',
'__version__': '1.0',
'dataCell': array([[array([[arra...pe=object)}
其中,scipy读入的mat文件是个dict类型,会有很多不相关的keys,一般输出四种keys:__globals__,__header__,__version__,data。其中最后一个data才是我们要的数据。
本例中,数据为 dataCell ,内容为
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
array([[array([[array(['wty0.0'], dtype='<U6')]], dtype=object),
array([[array(['-30deg'], dtype='<U6')]], dtype=object),
array([[ 0.00000000e+00, -8.66025400e+00, 0.00000000e+00, ...,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00],
[ 1.31815433e-01, -8.66003375e+00, 3.20285361e-12, ...,
-6.21551560e-19, 0.00000000e+00, 0.00000000e+00],
[ 2.63630865e-01, -8.65933419e+00, 1.29989166e-11, ...,
-3.17675810e-19, 0.00000000e+00, 0.00000000e+00],
...,
[ 4.58717705e+01, -2.75108745e+00, 2.14124086e-11, ...,
2.86948290e-17, -5.53482295e-17, 5.27271879e-15],
[ 4.60035859e+01, -2.75027966e+00, -4.46901743e-12, ...,
1.32056047e-17, -4.37313113e-17, -2.42826591e-16],
[ 4.61354014e+01, -2.75000000e+00, 2.89500769e-27, ...,
-2.77555756e-17, -1.30104261e-17, -1.48286602e-14]]),
array([[ 0.00000000e+00, 2.40730441e+00, 6.83370983e-08, ...,
2.87639504e+00, -3.90482776e-07, 2.65632451e-01],
[ 1.31815433e-01, 2.77247364e+00, 2.88899127e-04, ...,
1.27018538e+00, -2.19925908e-07, 1.26745599e-01],
[ 2.63630865e-01, 3.06865475e+00, 1.11303404e-03, ...,
6.74119805e-02, -9.25865826e-08, 2.27535649e-02],
...,
[ 4.58717705e+01, -3.25427728e+00, 5.09348887e-03, ...,
2.01213062e-02, 1.28660157e-03, 2.75940695e+00],
[ 4.60035859e+01, -3.15266928e+00, 1.21336612e-03, ...,
1.97145055e-02, 1.30781251e-03, 3.95909773e+00],
[ 4.61354014e+01, -3.04097330e+00, 1.01612056e-07, ...,
1.87656241e-02, 1.31095528e-03, 5.18427291e+00]])],
...,
dtype=object)
可以按照如下方式拼命取出 dataCell 中的各个元素
1
2
3
4
5
6
7
8
9
10
>>> targetw = []
>>> targetw.append(load_data['dataCell'][i][0][0][0][0]) # wty
'wty0.0'
>>> position = []
>>> position.append(load_data['dataCell'][i][1][0][0][0]) # deg
'-30deg'
>>> trajectory = np.zeros((tnum,1))
>>> trajectory = load_data['dataCell'][i][2]
>>> control = np.zeros((tnum,1))
>>> control = load_data['dataCell'][i][3]
得到的数据为 ndarray ,数据结构为
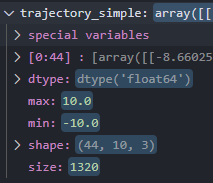
取出其中 wty 的数值,可以借助 strip 砍掉 “wty” 三个字符。注意 strip 返回的是一个字符串,需要通过强制格式转换转为数字
1
2
wt = wty.strip('wty') # 0.0
wt = float(wt)
提取 trajectory 中的第一行数据,最后一行数据,以及 wt,合并后形成一个新的向量,借助 np.hstack 实现:
1
2
3
trow = trajectory.shape[0]
vec = np.hstack((trajectory[0,1:4],trajectory[trow-1,1:4],wt))
# trajectory: t, rx, ry, rz, vx, ...; [1:4] is rx ry and rz
2. list
列表(list)是用来存储一组有序数据元素的数据结构,元素之间用逗号分隔。列表中的数据元素应该包括在方括号中,而且列表是可变的数据类型,一旦创建了一个列表,你可以添加、删除或者搜索列表中的元素。在方括号中的数据可以是 int 型,也可以是 str 型。
新建一个空列表
1
A = []
当方括号中的数据元素全部为int类型时,这个列表就是int类型的列表。str类型和混合类型的列表类似
1
2
3
A = [1,2,3]
A = ["a",'b','c'] # 单引号和双引号都认
A = [1,"b",3]
2.1. 复制
列表的复制和字符串的复制类似,也是利用 * 操作符
1
2
A = [1,2,3]
A*2 # A = [1,2,3,1,2,3]
2.2. 合并
列表的合并就是将两个现有的list合并在一起,主要有两种实现方式,一种是利用+操作符,它和字符串的连接一致;另外一种用的是extend()函数。
直接将两个列表用+操作符连接即可达到合并的目的,列表的合并是有先后顺序的。
1
2
3
4
5
a = [1,2]
b = ['a','b']
m = ["c","c"]
c=a+b+m # c = [1,2,'a','b','c','c']
d=b+a+m # d = ['a','b',1,2,'c','c']
将列表b合并到列表a中,用到的方法是a.extend(b),将列表a合并到列表b中,用到的方法是b.extend(a)。
2.3. 插入新元素
向列表中插入新元素。列表是可变的,也就是当新建一个列表后你还可以对这个列表进行操作,对列表进行插入数据元素的操作主要有 append() 和 insert() 两个函数可用。这两个函数都会直接改变原列表,不会直接输出结果,需要调用原列表的列表名来获取插入新元素以后的列表。
函数 append() 是在列表末尾插入新的数据元素,如下:
1
2
a = [1,2]
a.append(3) # a = [1,2,3]
函数 insert() 是在列表指定位置插入新的数据元素,如下:
1
2
3
4
a = [1,2,3]
a.insert(3,4) # a = [1,2,3,4],在列表第四位(从0开始算起)插入4
a = [1,2]
a.insert(2,4) # a = [1,2,4,3],在列表第三位(从0开始算起)插入4
2.4. 获取列表中的值
获取指定位置的值利用的方法和字符串索引是一致的,主要是有普通索引和切片索引两种。
- 普通索引:普通索引是活期某一特定位置的数,如下:
1
2
3
4
5
>>> a = [1,2,3]
>>> a[0] # 获取第一位数据
1
>>> a[2]
3
- 切片索引:切片索引是获取某一位置区间内的数,如下:
1
2
3
>>> a = [1,2,3,4,5]
>>> a[1:3] # 获取第2位到第4位的数据,不包含第4位
[2,3]
假设 a = [1,2,3,4,5,6,7,8,9],对应的标号为 [0,1,2,3,4,5,6,7,8];
print a[1:2:3] 输出为2 ,从下标表为1的地方开始到小于下标为2的位置,其中3为步长;
print a[1:4:1] 输出为2,3,4,以上面类似,只是步长为1了;
print a[1::1] 输出为2,3,4,5,6,7,8,9。中间为空表示默认,则从小标为1到最后;
print a[-1:-4:-1] 反向索引,从最后一位开始放过来取值,注意这里的步长要为-1,因为反向。
3. tuple
tuple,元组,与列表 list 类似,不同之处在于元组(指向)的元素不能修改。一般来说,tuple 是不可变的(immutable)可以包含多种类型成员的数据结构,list 是可变的包含同类型成员的数据结构。
元组使用小括号,列表使用方括号。元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。如果创建一个空元组,直接使用小括号即可;如果要创建的元组中只有一个元素,要在它的后面加上一个逗号’,’。
1
2
3
4
5
6
7
8
9
10
11
12
13
>>> temp = ()
>>> type(temp)
<class 'tuple'>
>>> temp = (1,)
>>> type(temp)
<class 'tuple'>
>>> temp = (1)
>>> type(temp)
<class 'int'>
>>> 8 * (8)
64
>>> 8 * (8,)
(8, 8, 8, 8, 8, 8, 8, 8)
最重要的好处是可以做dict的key(如果内部也是immutable的类型)。次一点的好处是由于确保不能修改,可以安全地在多个对象之间共享。
tuple类型对于Python自身来说是非常重要的数据类型,比如说函数调用,实际上会将顺序传入的参数先组成一个tuple;多返回值也是靠返回一个tuple来实现的。因为太常用,所以需要一个更有效的数据结构来提高效率,一个不可变的tuple对象从实现上来说可以比list简单不少。再比如说code对象会记录自己的参数名称列表,free variable名称列表等等,这些如果用list,就可能被从外部修改,这样可能导致解释器崩溃;那就只能选择改成一个函数每次都返回一个新的列表,这样又很浪费。所以即使是从解释器自身实现的角度上来说引入这样一个不可变的序列类型也是很重要的。
对程序员来说如果没有什么美学上的追求的话,tuple最大的便利在于它是一个hashable的类型,而且hash算法与值直接对应,这样在Python里很容易用多个值的组合来做key生成一个dict,比如说我们网络里有20台交换机,每个交换机有24个口,那要唯一标识每个口就需要用(交换机ID,口编号),这个tuple可以做dict的key的话,编写程序起来就很方便了。
函数如果有多个返回值,返回的是一个 tuple。
4. ndarray
Numpy是Python的一个扩充程序库,支持高阶大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。对于数据的运算,用矩阵会比python自带的字典或者列表快好多。
4.1. 概念
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引。
ndarray 对象是用于存放同类型元素的多维数组。
ndarray 中的每个元素在内存中都有相同存储大小的区域。
ndarray 内部由以下内容组成:
- 一个指向数据(内存或内存映射文件中的一块数据)的指针。
- 数据类型或 dtype,描述在数组中的固定大小值的格子。
- 一个表示数组形状(shape)的元组,表示各维度大小的元组。
- 一个跨度元组(stride),其中的整数指的是为了前进到当前维度下一个元素需要”跨过”的字节数。
创建一个 ndarray 只需调用 NumPy 的 array 函数即可:
1
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
参数说明
| 名称 | 描述 |
|---|---|
object |
数组或嵌套的数列 |
dtype |
数组元素的数据类型,可选 |
copy |
对象是否需要复制,可选 |
order |
创建数组的样式,C为行方向,F为列方向,A为任意方向(默认) |
subok |
默认返回一个与基类类型一致的数组 |
ndmin |
指定生成数组的最小维度 |
例子
1
2
3
4
5
6
7
8
>>> import numpy as np
>>> a = np.array([1,2,3])
>>> print (a)
[1, 2, 3]
>>> a = np.array([[1, 2], [3, 4]])
>>> print (a)
[[1, 2]
[3, 4]]
4.2. 数组属性
NumPy 数组的维数称为秩(rank),秩就是轴的数量,即数组的维度,一维数组的秩为 1,二维数组的秩为 2,以此类推。
在 NumPy中,每一个线性的数组称为是一个轴(axis),也就是维度(dimensions)。比如说,二维数组相当于是两个一维数组,其中第一个一维数组中每个元素又是一个一维数组。所以一维数组就是 NumPy 中的轴(axis),第一个轴相当于是底层数组,第二个轴是底层数组里的数组。而轴的数量——秩,就是数组的维数。
很多时候可以声明 axis。axis=0,表示沿着第 0 轴进行操作(沿着行移动),即对每一列进行操作;axis=1,表示沿着第1轴进行操作(沿着列移动),即对每一行进行操作。
4.3. 创建数组
numpy.zeros创建指定大小数组,数组元素以 0 来填充:
1
2
3
4
5
6
7
>>> import numpy as np
>>> x = np.zeros(5)
>>> print (x)
[0. 0. 0. 0. 0.]
>>> y = np.zeros((5,), dtype = np.int)
>>> print (y)
[0 0 0 0 0]
numpy.ones创建指定形状的数组,数组元素以 1 来填充:
1
2
3
4
5
6
7
8
9
>>> import numpy as np
[0. 0. 0. 0. 0.]
>>> x = np.ones(5)
[1. 1. 1. 1. 1.]
>>> print (x)
>>> y = np.ones((2,2), dtype = np.int)
>>> print (y)
[[1 1]
[1 1]]
numpy.arange创建数值范围并返回 ndarray 对象,函数格式如下:
1
numpy.arange(start, stop, step, dtype)
生成数组示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
>>> import numpy as np
>>> x = np.arange(5) # = np.arrange(0,1,5)
>>> print (x)
[0 1 2 3 4]
>>> x = np.arange(5, dtype = float)
>>> print (x)
[0. 1. 2. 3. 4.]
>>> x = np.arange(10,20,2)
>>> print (x)
[10 12 14 16 18]
>>> x = np.arange(0,1,0.1)
>>> print (x)
[ 0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9]
numpy.reshape在不改变数据内容的情况下,改变一个数组的格式,参数及返回值:
1
2
3
4
5
6
7
8
9
10
11
12
13
>>> import numpy as np
>>> x = np.arange(6)
>>> print (x)
[0 1 2 3 4 5]
>>> y = x.reshape((2,3))
>>> print (y)
[[0 1 2]
[3 4 5]]
>>> z = x.reshape(-1,2)
>>> print (z)
[[0 1]
[2 3]
[4 5]]
通过 reshape 生成的新数组和原始数组共用一个内存,也就是改变了原数组的元素,新数组的相应元素也将发生改变。
-1 表示要根据另一个维度自动计算当前维度。reshape(-1,2) 即我们想要2列而不知道行数有多少,让numpy自动计算。
numpy.linspace创建一个一维数组,数组是一个等差数列构成的,格式如下:
1
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
参数说明:
| 参数 | 描述 |
|---|---|
start |
序列的起始值 |
stop |
序列的终止值,如果 endpoint 为 true,该值包含于数列中 |
num |
要生成的等步长的样本数量,默认为 50 |
endpoint |
该值为 true 时,数列中包含 stop 值,反之不包含,默认是 true。 |
retstep |
如果为 true 时,生成的数组中会显示间距,反之不显示。 |
dtype |
ndarray 的数据类型 |
示例:
1
2
3
4
>>> import numpy as np
>>> a = np.linspace(1,10,10)
>>> print(a)
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
4.4. 数组拼接
两个拼接数组的方法:
np.vstack() 在竖直方向上堆叠
np.hstack() 在水平方向上平铺
1
2
3
4
5
6
7
8
9
10
11
12
13
14
>>> import numpy as np
>>> arr1=np.array([1,2,3])
>>> arr2=np.array([4,5,6])
>>> print np.vstack((arr1,arr2))
[[1 2 3]
[4 5 6]]
>>> print np.hstack((arr1,arr2,arr1))
[1 2 3 4 5 6 1 2 3]
>>> a1=np.array([[1,2],[3,4],[5,6]])
>>> a2=np.array([[7,8],[9,10],[11,12]])
>>> print np.hstack((a1,a2))
[[ 1 2 7 8]
[ 3 4 9 10]
[ 5 6 11 12]]
4.5. list和array的区别
1
2
3
4
5
6
7
8
9
10
>>> import numpy as np
>>> a=np.array([1,2,3,4,55,6,7,77,8,9,99]) # transfer a list to an array
>>> b=np.array_split(a,3) # split the array into 3 parts
>>> print (b) # a list containing 3 arrays
[array([1, 2, 3, 4]), array([55, 6, 7, 77]), array([ 8, 9, 99])]
>>> print (b[0:2]+b[1:3]) # a list containing 4 arrays
[array([1, 2, 3, 4]), array([55, 6, 7, 77]), array([55, 6, 7, 77]), array([ 8, 9, 99])]
>>> c = np.hstack((brr1_folds[:2]+brr1_folds[1:3]))
>>> print (c) # list
[ 1 2 3 4 55 6 7 77 55 6 7 77 8 9 99]
5. dict
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值 key=>value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示:
1
d = {key1 : value1, key2 : value2 }
5.1. 定义,更新和添加
1
2
3
4
5
6
7
8
9
10
>>> dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
>>> dict['Age'] = 8 # 更新
>>> dict['School'] = "RUNOOB" # 添加
>>> print "dict['Age']: ", dict['Age']
>>> print "dict['School']: ", dict['School']
dict['Age']: 8
dict['School']: RUNOOB
>>> del dict['Name'] # 删除键是'Name'的条目
>>> dict.clear() # 清空字典所有条目
>>> del dict # 删除字典
5.2. 内置函数
1
2
3
4
cmp(dict1, dict2) # 比较两个字典元素
len(dict) # 计算字典元素个数,即键的总数
str(dict) # 输出字典可打印的字符串表示
type(dict) # 返回输入的变量类型(字典类型)
5.3. 内置方法
1
2
3
4
5
6
7
8
9
10
11
12
dict.clear() # 删除字典内所有元素
dict.copy() # 返回一个字典的浅复制
dict.fromkeys(seq[, val]) # 创建一个新字典,以序列 seq 中元素做字典的键,val 为字典所有键对应的初始值
dict.get(key, default=None) # 返回指定键的值,如果值不在字典中返回default值
dict.has_key(key) # 如果键在字典dict里返回true,否则返回false
dict.items() # 以列表返回可遍历的(键, 值) 元组数组
dict.keys() # 以列表返回一个字典所有的键
dict.setdefault(key, default=None) # 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default
dict.update(dict2) # 把字典dict2的键/值对更新到dict里
dict.values() # 以列表返回字典中的所有值
pop(key[,default]) # 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。
popitem() # 返回并删除字典中的最后一对键和值。
字典值可以没有限制地取任何python对象,既可以是标准的对象,也可以是用户定义的,但键不行。
5.4. 特性
两个重要的点需要记住:
- 不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住;
- 键必须不可变,所以可以用数字,字符串或元组充当,所以用列表就不行。
5.5. OrderedDict
有序字典,可以按字典中元素的插入顺序来输出。有序字典的作用只是记住元素插入顺序并按顺序输出。如果有序字典中的元素一开始就定义好了,后面没有插入元素这一动作,那么遍历有序字典,其输出结果仍然是无序的,因为缺少了有序插入这一条件,所以此时有序字典就失去了作用,所以有序字典一般用于动态添加并需要按添加顺序输出的时候。
OrderedDict 使用前必须引入包 collections。
下面是插入元素的操作
1
2
3
4
5
6
7
8
import collections
my_order_dict = collections.OrderedDict()
my_order_dict["name"] = "lowman"
my_order_dict["age"] = 45
my_order_dict["money"] = 998
my_order_dict["hourse"] = None
for key, value in my_order_dict.items():
print(key, value)
输出
1
2
3
4
name lowman
age 45
money 998
hourse None
而如果在定义有序字典时初始化了初始值,并没有按序添加的操作,那么遍历时仍然是无序的。如
1
2
3
4
import collections
my_order_dict = collections.OrderedDict(name="lowman", age=45, money=998, hourse=None)
for key, value in my_order_dict.items():
print(key, value)
输出
1
2
3
4
hourse None
age 45
money 998
name lowman
6. 参考文献
[1] CDA数据分析师. Python基础知识详解(三):数据结构篇.
[2] RUNOOB.COM. NumPy 从数值范围创建数组.