
绪论。
- 1. 什么是人工智能
- 2. 人工智能的发展历史
- 3. 人工智能的组成和结构
- 4. 人工智能的标志性成果
1. 什么是人工智能
1.1. 人工智能
- 智能:学习和解决问题的能力。
智能是人类所具有的一种综合性能力,其内涵丰富且复杂。从感知方面来看,人类能够通过各种感官如视觉、听觉、嗅觉、味觉和触觉来获取外界环境的信息。例如,眼睛可以看到五彩斑斓的世界,识别物体的形状、颜色和大小;耳朵能听到各种声音,分辨出语言、音乐和自然界的声响等。这种感知能力是智能的基础,它让我们与外界建立联系,获取必要的信息以适应环境。
—–机械工业出版社2020《人工智能导论》
- 人工智能(Artificial Intelligence, AI),亦称机器智能,指由人制造出来的机器所表现出来的智能,是机器对人类智能的一种模拟。
人工智能(Artificial Intelligence,简称 AI)是一门研究如何使计算机能够模拟人类智能的学科和技术。它试图让计算机具有感知、学习、推理、决策等类似于人类的智能行为。从学科角度来看,人工智能是计算机科学的一个重要分支,它融合了数学、心理学、语言学、控制论等多个学科的知识。从能力角度而言,人工智能旨在赋予计算机系统以人类智能的某些特征,使其能够解决原本需要人类智能才能解决的问题。
—–机械工业出版社2020《人工智能导论》
人工智能的核心问题包括构建能够和人类类似甚至超越人类的推理、知识、规划、学习、交流、感知、使用工具和操控机械的能力等。研究内容包括但不限于机器学习、知识表示、推理、规划、自然语言处理、计算机视觉、机器人学、专家系统等。
1.2. 机器学习
机器学习(Machine Learning, ML)是实现人工智能的一种核心方法。它的核心思想是:不直接编程告诉机器每一步该怎么做,而是让机器通过 “数据” 自己学习如何完成任务。通过算法分析大量数据,从中找出规律或模式,然后利用这些规律对新的情况做出判断或预测。模型学习得数据越多,通常就越准确。
常见的机器学习方法包括决策树、支持向量机(SVM)、随机森林、以及各种传统的神经网络等。
1.3. 深度学习
深度学习(Deep Learning, DL)是机器学习的一个子领域,它使用一种叫做 “深度神经网络” 的复杂模型来进行学习。“深度” 的含义指的是神经网络的结构有很多层(隐藏层),这些层级结构使得机器能够从数据中提取不同层级的特征(从低级特征到高度抽象的特征)。
1.4. 模式识别
模式识别(Pattern Recognition, PR)是一个经典的工程领域,专注于从数据中自动发现和识别规律、模式。这些模式可以是图像、声音、文本中的任何有规律的信息。
模式识别与机器学习的目标高度一致。在早期,模式识别更多依赖于传统的数理统计方法和专家设计的特征提取器。而现代的模式识别几乎完全依赖于机器学习(尤其是深度学习)来自动学习和识别模式。可以说,机器学习为模式识别提供了最强大的工具。
1.5. 关系图
flowchart TD
A[人工智能<br>AI] --> B[实现AI的一种核心途径]
B --> C[机器学习<br>ML]
C --> D[机器学习的一个子集<br>最具代表性的实现方式]
D --> E[深度学习<br>DL]
F[模式识别<br>PR] -.-> C
A -- 包含 --> C
C -- 包含 --> E
F -- 与ML目标重合<br>广泛采用ML方法 --> C
2. 人工智能的发展历史
| 阶段 | 时间 | 主要特征 | 代表事件 |
|---|---|---|---|
| 萌芽与理论探索期 | 1940s–1950s | 理论奠基,提出图灵测试 | 1950年图灵提出图灵测试, 1956年达特茅斯会议确立AI学科 |
| 符号主义主导期 | 1956–1970 | 基于规则和逻辑推理的专家系统 | 1958年LISP语言诞生, 1966年ELIZA对话系统 |
| 第一次寒冬期 | 1974–1980 | 技术瓶颈,资金撤出,研究停滞 | 1973年莱特希尔报告, AI研究经费大幅削减 |
| 连接主义复兴期 | 1980–1990 | 神经网络研究复兴,专家系统商业化 | 1986年反向传播算法提出 |
| 技术积累期 | 1990–2010 | 机器学习兴起,统计方法普及 | 1997年深蓝击败国际象棋冠军卡斯帕罗夫 |
| 深度学习爆发期 | 2010–2018 | 深度学习突破,大数据与GPU计算 | 2012年AlexNet在ImageNet竞赛获胜, 2016年AlphaGo击败李世石 |
| 大模型时代 | 2018–至今 | 大语言模型与生成式AI崛起 | 2018年BERT模型发布, 2022年ChatGPT现象级应用 |
2.1. 萌芽与理论探索期
- 时间:1940s–1956年
- 技术路线:符号主义(Symbolism)
- 关键事件:
- 1943年,麦卡洛克和皮茨提出神经元数学模型,奠定神经网络理论基础。
- 1950年,图灵提出 “图灵测试”,定义了机器智能的判定标准。
- 深层原因:
- 理论突破:数学逻辑、神经科学和计算机科学的交叉融合,为 AI 提供了理论雏形。
- 技术需求:二战后密码破译、弹道计算等需求推动计算机技术快速发展。
2.1.1. 图灵测试
图灵测试(Turing Test),原名 “模仿游戏”(The Imitation Game),是由英国计算机科学家、密码学家、逻辑学家阿兰·图灵(Alan Turing)在1950年的哲学论文《计算机器与智能》(Computing Machinery and Intelligence)中提出的一个关于机器能否思考的思想实验。其核心目的并非直接回答「机器能否思考」这个复杂的哲学问题,而是提供一个基于行为的、可操作的替代方案:如果一台机器的行为表现得和一个思考者完全无法区分,那么我们就应当承认它在 “思考”。
图灵测试的原始设定是一个简单的三人游戏,包括一个人类询问者(Interrogator)、一个人类(Man)和一台机器(Machine)。整个过程通过文本(例如打字机或电脑终端)进行交流,以避免通过声音或外观来辨别。
-
物理隔离:询问者被安排在一个房间里,通过终端与另外两个房间里的实体(一个人和一台机器)进行纯文本对话。询问者不知道哪个对应人,哪个对应机器。
-
对话过程:询问者可以提出任何他想到的问题,内容不限(例如,“请给我写一首关于咖啡的诗”、“你对昨晚的足球比赛怎么看?”、“45893乘以99157等于多少?”)。
-
测试目标:
-
机器的目标是尽可能模仿人类,通过其回答让询问者相信它才是那个“人”。
-
人类的目标是尽力帮助询问者,通过真诚的回答证明自己才是真人。
-
-
评判标准:经过一段时间的交谈(例如5分钟)后,询问者需要判断哪个对话者是机器,哪个是人。如果询问者无法可靠地区分机器和人(例如,错误率超过 $30\%$),那么这台机器就被认为通过了图灵测试。
图灵测试自 1950 年由艾伦·图灵提出以来,一直是人工智能领域一个极具争议又引人入胜的目标。它的核心思想是:如果一台机器能够通过文本对话与人类进行交流,并且使其超过 $30\%$ 的交互者无法区分它到底是人还是机器,那么就可以认为这台机器通过了测试,展现了智能。
2025年7月29日新闻,MiniMax 大模型通过人机辩论图灵测试
2025年4月2日,GPT-4.5成功通过图灵测试
不过,对于“通过”图灵测试,需要明确以下几点:
-
“通过” 不等于 “超越”:测试的核心是“模仿”和“欺骗”,而非真正理解和拥有智能。它衡量的是机器行为的 “拟人性”(humanlikeness),而非直接的 “智能” 水平。
-
测试形式的演变:传统的图灵测试多是单轮、开放域的文本对话。但现在的测试形式更加多样,例如 “三方测试”(询问者同时与一个人和一个机器对话并区分),或者参与的 “人机辩论” 这种更高维度的检验。
-
局限性:许多学者认为,即便机器在对话中骗过了人类,也不意味着它拥有了意识、情感或真正的理解能力。它可能只是模式匹配和统计预测的高手。图灵测试更关注社交智能和语言风格的模仿,而非深度的推理和创造力。
2.2. 符号主义黄金时期
- 时间:1956–1974年
- 技术路线:符号推理与专家系统
- 关键事件:
- 1956年达特茅斯会议,麦卡锡、明斯基、香农等正式提出 “人工智能” 概念,标志学科诞生。与会者们极度乐观,认为在几十年内就能造出与人相媲美的智能机器。
- 1966年,ELIZA聊天机器人问世,模拟心理治疗师对话。
- 深层原因:
- 资金支持:美国国防高级研究计划局(Defense Advanced Research Projects Agency,DARPA)等机构大力资助,推动早期技术研发。
- 乐观预期:研究者认为通过符号规则即可模拟人类全部智能,导致过度承诺。
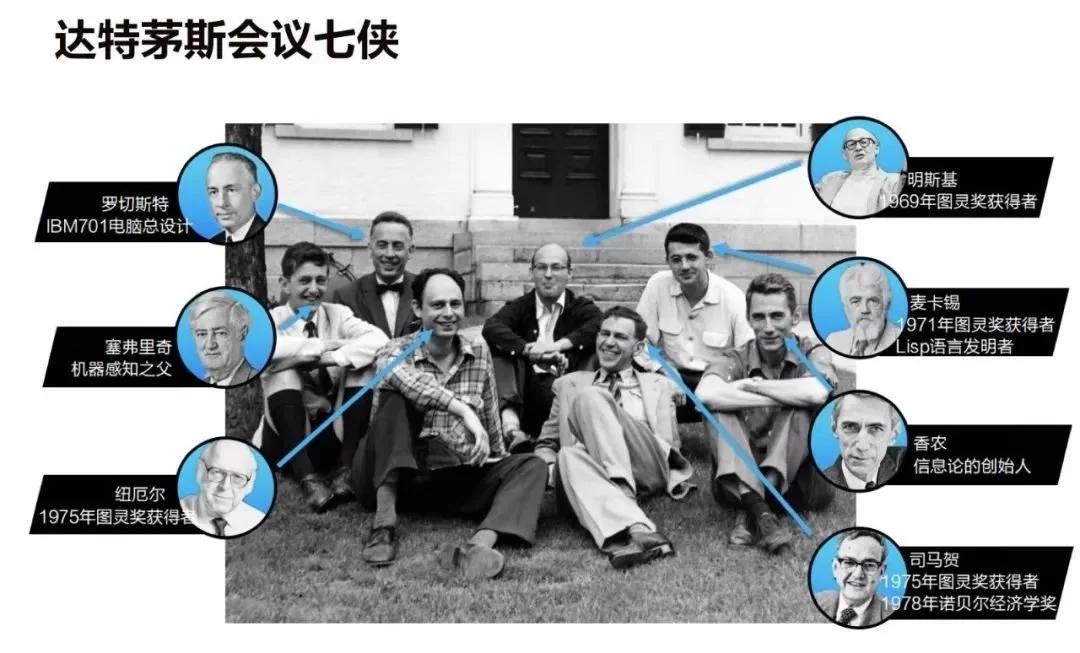
达特茅斯会议于 1956 年 6 月 18 日至 8 月 17 日在美国汉诺斯小镇的达特茅斯学院举行,麦卡锡、明斯基、香农等学者首次正式提出 “人工智能”(Artificial Intelligence) 术语,标志着该学科的诞生。会议聚集了来自数学、计算机科学等领域的 30 余位研究者,纽厄尔与西蒙展示了首个可工作的 AI 程序 “逻辑理论家”,塞缪尔开发的跳棋程序则开创了机器学习先例。符号主义、连接主义与行为主义三大学派的技术路线在此次会议中初现雏形。
- 符号主义:主张基于逻辑规则的符号推理系统
- 连接主义:探索神经网络模拟人脑工作机制
- 行为主义:强调通过环境交互实现智能涌现
2.2.1. 符号主义(Symbolicism)
| 维度 | 内容 |
|---|---|
| 哲学假设 | • “思维即计算”:智能行为可还原为对离散符号的形式化操作。 • “物理符号系统假说”(Newell & Simon, 1976):只要能进行符号存储、复制、组合、比较的系统,就具备一般智能。 |
| 技术路线 | 知识库 + 推理机 + 解释器 • 知识库:一阶谓词、产生式规则、语义网络、框架系统。 • 推理机:前向/反向链、归结原理、启发式搜索(A*、Minimax)。 • 解释器:把推理轨迹翻译成人类可读的“为什么”。 |
| 典型算法 | • 归结定理证明(Resolution) • Rete 网络匹配(规则引擎) • 约束满足(CSP) |
| 经典系统 | • 1965 DENDRAL:化学分子结构解析 • 1972 MYCIN:细菌感染诊断,准确率超过人类住院医师 • 1980 XCON:DEC 计算机的自动配置,每年节省 4000 万美元 |
| 优势 | ✓ 可解释性强:推理链就是“逻辑证明”。 ✓ 高精度封闭领域:规则完全覆盖时几乎零误差。 |
| 瓶颈 | ✗ 知识获取瓶颈:规则需要专家手工编写,成本高、易冲突。 ✗ 脆弱性:遇到规则未覆盖的“边缘情况”立即崩溃。 ✗ 组合爆炸:搜索空间指数级膨胀,硬件无法承受。 |
| 现代演化 | • 符号-神经融合:Neural-Symbolic Computing、逻辑张量网络(LTN) • 知识图谱 + LLM:用大规模语言模型自动生成符号规则,再经逻辑验证 |
2.2.2. 连接主义(Connectionism)
| 维度 | 内容 |
|---|---|
| 哲学假设 | • “心智即网络”:智能来自大量简单单元(神经元)通过权重连接形成的统计模式。 • 分布式表征:知识不存在于某个符号,而分布于整个网络的权重矩阵中。 |
| 技术路线 | 数据 → 多层可微分网络 → 误差反向传播 → 权重更新 → 泛化 |
| 典型算法 | • 反向传播(Rumelhart, Hinton & Williams, 1986) • 卷积神经网络(LeCun, 1989) • Transformer 自注意力(Vaswani et al., 2017) |
| 经典系统 | • 1989 LeNet:手写数字识别 • 2012 AlexNet:ImageNet 图像分类突破 • 2022 ChatGPT:千亿参数大语言模型 |
| 优势 | ✓ 端到端学习:自动从原始数据提取特征,减少人工设计。 ✓ 大规模并行:GPU/TPU 算力红利下呈指数级提升。 ✓ 鲁棒性:对噪声、缺失数据有一定容忍度。 |
| 瓶颈 | ✗ 黑盒性:难以解释内部决策逻辑。 ✗ 数据饥渴:需要海量标注或自监督数据。 ✗ 分布外脆弱:输入轻微扰动可能导致灾难性错误。 |
| 现代演化 | • 可解释 AI(SHAP、Attention 可视化) • 小样本/零样本学习(Prompt Engineering、In-Context Learning) • 神经-符号接口:用逻辑约束微调大模型,提升一致性 |
典型应用:DeepSeek 等
2.2.3. 行为主义(Behaviorism / Emergentism)
| 维度 | 内容 |
|---|---|
| 哲学假设 | • “智能源于行为而非表征”:强调感知-动作闭环与环境耦合,而非内部符号或神经网络。 • 具身认知:智能体必须先有身体,才能在真实物理世界中通过交互涌现智能。 |
| 技术路线 | 感知 → 直接映射 → 动作 → 环境反馈 → 适应/学习 |
| 典型算法 | • 强化学习:Q-Learning、SARSA、PPO • 进化算法:遗传算法(GA)、遗传规划(GP) • 群体智能:蚁群算法、粒子群优化 |
| 经典系统 | • 1990 Brooks 六足机器人 Genghis:无地图导航,基于“包容架构” • 1997 Floreano 进化神经网络无人机:在线进化飞行控制 • 2016 DeepMind AlphaGo:蒙特卡洛树搜索 + 深度强化学习 • 2023 Boston Dynamics Atlas:跑酷、空翻等复杂运动技能 • 2025 宇树科技:机器人集群协同 + 机器人运动会 |
| 优势 | ✓ 无需精确模型:直接从交互中学习策略。 ✓ 开放环境适应:对动态、未知环境具备实时调整能力。 ✓ 多智能体涌现:简单个体规则 → 群体复杂行为(蚁群、鸟群)。 |
| 瓶颈 | ✗ 样本效率低:需要大量交互数据,真实环境代价高。 ✗ 奖励设计困难:稀疏、延迟或误导的奖励导致学习失败。 ✗ 安全性:探索过程中的危险动作难以预测。 |
| 现代演化 | • 离线强化学习(Offline RL):用历史数据预训练,降低在线风险 • 模拟到现实(Sim2Real):高保真物理仿真 + 领域随机化 • 大模型 + 机器人:PaLM-E、RT-2 把多模态大模型嵌入机器人控制回路 |
行为主义的代表方法 强化学习 的典型应用(走楼梯):https://www.bilibili.com/video/BV1Cy421e71b
2.2.4. 三主义对比一览
| 维度 | 符号主义 | 连接主义 | 行为主义 |
|---|---|---|---|
| 知识形态 | 显式符号规则 | 隐式权重分布 | 动态行为策略 |
| 学习方式 | 人工编码 | 数据驱动 | 交互试错 |
| 解释性 | 强 | 弱 | 中 |
| 对噪声容忍 | 弱 | 强 | 强 |
| 典型硬件 | 推理服务器 | GPU/TPU 集群 | 传感器 + 执行器 |
| 现代融合 | 知识图谱 + LLM | 神经-符号接口 | 大模型控制机器人 |
三种主义并非互斥,而是在各自“最擅长的战场”继续演化,并通过 “神经-符号-行为” 三重融合,向更通用的人工智能迈进。
2.3. 第一次寒冬期
- 时间:1974–1980年
- 技术瓶颈:
- 符号主义局限:规则系统无法处理模糊、不确定的现实问题。
- 计算能力不足:硬件性能低下,无法支持复杂模型训练。 关键事件:
- 1973 年,英国詹姆斯·莱特希尔(James Lighthill)发布报告严厉批评了 AI 未能实现其宏伟承诺,导致英国和美国大幅削减研究经费。
- 1974年 DARPA 大幅削减 AI 预算,研究停滞。
- 深层原因:
- 技术泡沫破裂:早期目标(如通用翻译、类人机器人)远超当时技术能力。
- 资金与信任危机:政府与企业对AI失去信心,投入断崖式下跌。
2.3.1. 寒冬来临前的狂热
-
达特茅斯会议的乐观:AI 领域的创始人们在会议上是极度乐观的。他们相信 “机器的每个方面或学习的任何其他特征,原则上都可以被精确地描述,从而可以制造出一台机器来模拟它”,并且认为这项研究将在一代人内取得重大突破。
-
大量资金涌入:这种乐观情绪感染了政府机构,尤其是美国的国防高级研究计划局(DARPA) 和英国的政府机构。它们为AI研究提供了巨额、几乎无限制的资金,期望能获得革命性的军事或技术优势。
-
早期成功的幻觉:研究者们开发出了一些令人瞩目的系统,如能解决代数应用题的STUDENT、能证明几何定理的Geometry Theorem Prover,以及能与人进行简单对话的ELIZA聊天机器人。这些成功(尽管今天看来很初级)进一步强化了“AI即将成功”的信念。
2.3.2. 理想的破灭
寒冬的到来源于几个无法克服的根本性挑战。
-
计算能力的严重匮乏(The Brute Force Problem)
-
当时的计算机(如IBM 7090)内存以KB计,速度以KHz计,与今天的计算机有天壤之别。
-
任何稍微复杂一点的AI计算(如搜索一个可能性的空间)都会迅速耗尽所有内存和计算资源。AI程序运行成本极高且极其缓慢。
-
-
组合爆炸问题(The Combinatorial Explosion)
-
早期AI(符号主义AI)严重依赖于逻辑推理和搜索。但许多现实世界问题的搜索空间会随着变量增加呈指数级增长。
-
例如,在国际象棋中,每一步的可能走法都会衍生出无数种后续局面,其总量甚至超过宇宙中的原子数。当时的算法和算力完全无法有效处理这种爆炸式的复杂性。AI系统只能在极其简化的“玩具问题”上工作。
-
-
知识的缺失:常识与世界知识(The Commonsense Knowledge Problem)
-
这是最致命的问题之一。研究者发现,机器可以轻松证明复杂的数学定理,但却无法理解一个三岁小孩都懂的常识,例如:
-
“鸟会飞”(那企鹅呢?受伤的鸟呢?)
-
“水是湿的”(什么是‘湿’?)
-
“如果弗雷德在餐厅,那么他的脚在地板上”(但如果他坐在椅子上呢?如果餐厅地板塌了呢?)
-
这导致了莫拉维克悖论(Moravec’s Paradox)所描述的现象:让计算机像成人一样进行推理和下棋是相对困难的,但让它们具备一岁孩子的感知和运动技能却是极其困难的。
-
-
机器缺乏对世界的基本认知(即“常识”),这使得它无法理解语境、处理异常情况,显得非常 “脆弱” 和 “愚蠢”。将人类所有常识形式化并输入计算机被证明是一个几乎不可能完成的任务。
-
-
算法与理论的局限性
-
神经网络(连接主义)的第一次低谷:1969年,AI领域的权威马文·明斯基(Marvin Minsky)和西摩尔·派普特(Seymour Papert) 出版了著作《感知器》(Perceptrons)。他们在数学上证明了单层感知器(最简单的神经网络模型)连 “异或”(XOR)这样简单的逻辑问题都无法解决,并悲观地推测更复杂的多层网络也存在巨大局限。
-
这一结论(虽然后来被证明是过于悲观的)极大地打击了神经网络学派的研究,导致其经费被切断,研究陷入停滞长达近 20 年。资金和注意力都集中在了看似更有希望的符号主义 AI 上,而后者也很快遇到了天花板。
-
2.3.3. 寒冬的到来
英国政府(尤其是科学研究委员会SRC)对投入巨资的 AI 研究迟迟未能交付实际成果感到不满和疑虑。他们委托应用数学家莱特希尔对AI领域进行全面评估,以决定未来的资助政策。
1973 年,莱特希尔发表的报告极其悲观和严厉。报告将AI研究分为三类:
-
高级自动化(Advanced Automation):在特定领域有用,但价值被夸大。
-
构建中枢神经系统(Building Central Nervous Systems):即神经网络,被认为是彻底的失败。
-
基于计算机的智力研究(Computer-based Studies of Intelligence):即符号主义AI,莱特希尔认为其成果微不足道,且遭遇了组合爆炸等无法克服的障碍。
报告的核心论点是,AI 研究未能实现其任何宏伟承诺,所谓的 “成功”只是在一个个孤立的 “玩具世界” 里取得的,无法扩展到现实世界。他预言 AI 领域将遭遇 “泡沫破灭”。该报告产生了毁灭性的影响。它直接导致英国政府几乎完全停止了对AI研究的资助。报告也迅速传到大西洋彼岸,影响了美国和其他国家资助机构的决策。莱特希尔报告之后,寒冬正式降临:
-
资金急剧枯竭:DARPA等主要资助方大幅削减了对AI基础研究的资金。他们不再为“宏伟的智能梦想”买单,转而资助那些有明确、实用目标的项目。
-
研究陷入停滞:许多大学的研究项目被关闭,实验室解散。整个领域的研究进展变得极其缓慢。
-
污名化:“人工智能”这个词一度变得不受欢迎,研究者们为了申请经费,不得不使用其他名称,如“informatics”、“机器学习”、“知识系统”等。
-
研究方向转变:寒冬迫使幸存下来的研究者们变得更加务实,从追求“通用人工智能”转向解决更具体、更狭窄的问题。这间接为80年代专家系统的崛起埋下了伏笔,因为专家系统至少在商业应用上看到了成功的希望。
2.4. 专家系统与知识工程
- 时间:1980–1987年
- 技术路线:知识工程(Knowledge Engineering)
关键事件:
- 1980年代,专家系统(如MYCIN医疗诊断系统、XCON计算机配置系统)商业化。
- 1986年,反向传播算法重新激活神经网络研究。
- 深层原因:
- 实用化转向:从“通用智能”转向“特定领域专家系统”,降低技术难度。
- 企业需求:工业界需要自动化决策工具,推动专家系统落地。
2.4.1. 专家系统
专家系统(Expert Systems)是一种模仿人类专家在特定领域内进行决策的计算机程序。它的核心思想是:智能行为源于知识,而非通用的推理机制。也就是说,一个拥有大量专业知识的简单系统,其表现会远胜于一个拥有通用推理能力但缺乏知识的系统。其目标是捕获特定领域(如医疗诊断、化学分析、设备故障排查)人类专家的专门知识和经验,并将其提供给非专家使用。
专家系统通常包含三个核心部分:
-
知识库 (Knowledge Base):系统的核心。存储着从人类专家那里提取的领域知识,通常以 “如果-那么” (If-Then) 规则的形式存在。
- 例如(医疗领域):如果 生物体是革兰氏阳性 且 形态是球状 且 生长结构是链状,那么 该生物体是链球菌(置信度0.7)。
-
推理引擎 (Inference Engine):系统的大脑。它负责调用和执行知识库中的规则。其工作方式主要有两种:
-
前向链推理 (Forward Chaining):从已知数据出发,逐步应用规则,推导出结论(数据驱动)。适用于监控、规划类问题。
-
后向链推理 (Backward Chaining):从假设的结论出发,反向寻找支持该结论的证据和规则(目标驱动)。适用于诊断、推理类问题。
-
-
用户界面 (User Interface):使用户可以与系统交互,输入信息并获取推理结果和解释。
决策树与专家系统的关系:
决策树是构建专家系统(尤其是基于规则的专家系统)的一种强大、直观且高效的工具。 它完美地解决了专家系统中知识表示和推理的问题。你可以把一个由决策树驱动的专家系统想象成:它的知识库是由决策树转化而来的规则集,它的推理引擎就是遍历这棵树的算法。
专家系统是一个更宏大的概念,它可以使用决策树,也可以使用其他多种知识表示和推理方法。决策树则是一种更具体、更基础的技术,它既可以独立作为分类工具,也可以作为大型智能系统(如专家系统)的一个组成部分。
2.4.2. 知识工程
知识工程是构建专家系统的过程和方法论。它涉及如何从人类专家那里提取、形式化、编码其知识到知识库中。从事这项工作的人被称为知识工程师。
知识工程是一个耗时且昂贵的 “瓶颈” 过程,一般包括:
-
知识获取:知识工程师与领域专家(如资深医生、地质学家)进行大量访谈,观察他们的工作,试图理解和记录其决策过程。
-
知识表示:将获取到的、往往是模糊的、基于经验的知识,转化为计算机可以理解和处理的明确形式(主要是规则)。
-
知识验证:测试编码后的知识库,确保其产生的结论与人类专家的判断一致。
2.4.3. 反向传播
当符号主义的专家系统如火如荼时,连接主义(神经网络)正在从第一次寒冬中复苏。
1986年,大卫·鲁姆哈特(David Rumelhart)等人发表的论文重新普及了反向传播(Backpropagation)算法,有效地解决了明斯基所说的多层神经网络训练难题。
这为神经网络的研究注入了强心剂,虽然当时并未立即挑战专家系统的地位,但为 20 多年后的深度学习革命埋下了最重要的伏笔。这条暗线预示着 AI 的另一条道路正在积蓄力量。
2.5. 第二次寒冬期
- 时间:1987–1993年
- 技术瓶颈:
- 专家系统局限:规则维护成本高昂,无法跨领域应用。
- 硬件成本高:LISP机等专用设备价格昂贵,难以普及。
- 关键事件:
- 1987 年,专家系统市场崩盘,AI 再次进入低谷。
- 深层原因:
- 商业化失败:企业发现专家系统投入产出比低,市场迅速萎缩。
- 技术路径固化:符号主义与连接主义之争未解决,缺乏新突破。
2.5.1. 专家系统的局限
专家系统是第二次AI热潮的明星,但其内在缺陷在广泛应用后暴露无遗:
-
脆弱性与窄领域:专家系统本质上是“知识盆景”。它们只在设计时预设的非常特定和狭窄的领域内有效(例如,诊断特定品牌的打印机故障)。一旦问题稍微超出边界,系统就会完全失效,无法像人类那样进行常识推理或举一反三。
-
知识获取瓶颈:构建专家系统的核心是从人类专家那里提取知识(“知识工程”)。这个过程极其困难、耗时且昂贵。专家系统非常脆弱。它们无法处理规则库中没有明确定义的情况。随着规则数量的增加(可达数千条),系统变得极其复杂、难以维护和更新,且容易产生矛盾。这被称为“知识获取瓶颈”——如何将人类专家的知识高效、准确地转化为机器规则是一个极其耗时费力的过程。
-
维护成本高昂:世界在变化,知识在更新。维护一个庞大的、基于规则的系统是一场噩梦。添加新规则常常会与旧规则产生难以预料的冲突,导致系统性能下降甚至崩溃。维护成本随着系统规模呈指数级增长,变得不可持续。

人们开始对于专家系统和人工智能的信任都产生了危机,一股强烈的声音开始对当前人工智能发展方向提出质疑,他们认为使用人类设定的规则进行编程,这种自上而下的方法是错误的。大象不玩象棋,但大象可以从现实中学会识别环境并作出判断,人工智能技术也应该拥有身体感知能力,从下而上才能实现真正的智能。这种观点是超前的,但也推动了后续神经网络技术的壮大和发展。
2.5.2. 专用硬件的失败
为了高效运行专家系统(其核心语言通常是 LISP 或 Prolog),许多公司(如 Symbolics, LMI)开发了专用的 LISP 机——为 LISP 语言量身定制的硬件工作站。这些机器性能卓越,但价格极其昂贵(通常在5万到10万美元以上)。

上世纪80年代初,日本政府制定了一个野心勃勃的十年规划,投资8.5亿美元,打算在 IT 领域内一举超越美国,建立全球的领导地位。日本的这个计划就是:第五代计算机。日本的第五代计算机有个宏大目标:抛弃冯诺依曼架构,采用新的并行架构,采用新的存储器,新的编程语言,以及能处理自然语言、图像的新操作方式。让第五代计算机具备推理和知识处理能力,换句话说,第五代计算机就是“人工智能计算机”。
前四代计算机都是所谓冯诺依曼架构,主要用于商业运算和信息处理。
经过六七十年代的高速发展,日本在消费类电子和汽车工业已经是世界领先。在半导体领域,日本组织了半导体协会,在很短的时间内就全面赶超了美国公司,占据了 DRAM 约 70% 的市场。Intel 公司甚至被迫从 DRAM 转向微型处理器(当然也因祸得福,这是后话)。日本觉得他们已经进入 “无人区”,必须要搞 “双创”,不能再跟踪美国,要变道超车。
问题求解和推理
通过计算机自身存储的信息(知识)得出问题的结论
知识库的管理
将知识作为一种可以处理、存储、检索的形式组织在一起。
智能接口
计算机能对自然语言,图形、图像进行判读,并给出回答
智能程序设计
对于给定的问题,能自动、快速地转换成程序。
近40年过去了,这四个目标依然进展缓慢,仅仅是第三个目标,机器学习才在最近几年取得了进展。 可见,当时的日本政府提出的计划太过超前,超越了时代。
日本在五代机上的计划,无意间 “忽悠” 了全世界,那些主要的大国为了防止落后,都奋起直追:
-
1983年,美国 DARPA 再次开始通过战略计算计划资助人工智能研究。
-
1984年,英国实施了 Alvey 计划,创建大规模并行计算机,支持知识工程研究。
-
德国西门子,法国 Bull, 英国 ICL 公司,则一起成立了欧洲计算机研究中心。
-
咱们国家也差点上了贼船,1990 年,中科院计算所设立了 “智能中心”,当时日本五代机已经进入尾声,汪成为、李国杰等老师走访了日本从事第五代计算机研究的实验室,发现该实验室自身都不用其研制出的机器!后来他们顶住压力,对智能计算机重新定位,果断地选择了高性能计算机的路子,开发了 “曙光” 系列高性能计算机。
在日本失去的十年中,美国主导的 PC 和工作站兴起,CPU 性能每隔 18 个月就翻一番(摩尔定律)。到了 80 年代中后期,基于 UNOS 的通用工作站(如 Sun, DEC, Apollo)和日益强大的个人计算机性能大幅提升,价格却远低于 LISP 机。

更致命的是,这些通用工作站上出现了高效的 LISP 编译器,使得在便宜得多的硬件上也能很好地运行专家系统。LISP 机失去了存在的市场价值,导致生产它们的公司纷纷倒闭。这对依赖它们的 AI 行业造成了巨大的硬件和象征性打击。
2.6. 机器学习与数据驱动
- 时间:1993–2010年
- 技术路线:统计机器学习(如SVM、随机森林、贝叶斯网络)
- 关键事件:
- 1997年,IBM深蓝击败国际象棋冠军卡斯帕罗夫。
- 2006年,Hinton提出“深度信念网络”(DBN),重启深度学习。
- 深层原因:
- 互联网爆发:提供海量数据,解决AI“燃料”问题。
- 计算力提升:GPU并行计算降低训练成本,支持复杂模型。
- 算法革新:统计学习理论成熟,机器学习成为主流。
2.6.1. 统计机器学习的崛起
这一时期是AI从 “基于规则的符号智能” 向 “基于统计的数据智能” 范式转移的核心阶段,它为2010年后的深度学习大爆发奠定了所有必要的基础。在第二次 AI 寒冬的废墟上,AI 研究并没有停止,而是转向了一条更加务实、以结果为导向的道路。研究者们放弃了直接构建 “通用人工智能” 的宏大目标,转而专注于解决具体的、有商业价值的任务。这一时期的核心理念是:“让数据自己说话”。AI 系统不再依赖于人类专家手动编写的大量规则,而是通过机器学习算法从海量数据中自动学习模式和规律。
这一时期的绝对主角是「统计机器学习」(Statistical Machine Learning)。其背后的哲学是:学习是一个基于数据概率分布的统计推断问题。主流算法包括:
-
支持向量机(SVM - Support Vector Machine):
-
原理:通过寻找一个最优的超平面来对数据进行分类,这个超平面能最大化不同类别数据之间的 “边界”。
-
优势:理论基础坚实(统计学习理论,VC维)、在小样本数据集上表现优异、对高维数据处理效果好。在21世纪初的十年里,SVM 几乎是机器学习领域的 “万能药”,占据了统治地位。
-
-
集成方法(Ensemble Methods):
-
原理:“三个臭皮匠,顶个诸葛亮”。通过构建并结合多个弱学习器(如决策树)来完成预测,以获得更准确、更稳定的模型。
-
代表算法:
-
随机森林(Random Forest):是一种典型的自举汇聚(Bootstrap Aggregating,Bagging)方法,通过构建多棵决策树并进行投票来做出决策,有效避免了单棵决策树容易过拟合的问题。
-
梯度提升机(Boosting Methods, 如 AdaBoost): sequentially(顺序地)训练一系列弱学习器,每一个都专注于修正前一个的错误。
-
-
-
贝叶斯网络(Bayesian Networks):
- 原理:一种概率图模型,使用图形模式来表示变量之间的条件依赖关系。它结合了图论和概率论,非常适合处理不确定性推理问题(如医疗诊断、风险评估)。
-
其他重要技术:
-
核方法(Kernel Methods):与 SVM 紧密结合,通过巧妙的数学变换(核技巧)将线性不可分的数据映射到高维空间,使其变得线性可分。
-
逻辑回归(Logistic Regression):简单而强大的线性分类模型,至今仍是许多分类任务的基础。
-
图模型(Graphical Models):提供了一个统一的框架来理解和表达复杂的概率关系。
-
2.6.2. 关键事件详解
-
IBM深蓝击败国际象棋冠军卡斯帕罗夫(1997)
-
意义:这一事件虽然主要依靠的是暴力计算(大规模并行计算和高效的搜索算法)而非真正的“智能”,但它具有巨大的象征意义和公关效应。
-
影响:它向世界宣告,计算机在特定的、规则明确的智力活动上可以超越人类最顶尖的大脑。这重新点燃了公众对AI的兴趣,并证明了大规模计算能力的重要性,为后续发展铺平了道路。
-
-
杰弗里·辛顿(Geoffrey Hinton)提出“深度信念网络”(2006)
-
背景:神经网络的研究自第二次寒冬后一直处于边缘地位。虽然理论可行,但训练深层的神经网络非常困难(梯度消失/爆炸问题),且计算成本高昂。
-
突破:辛顿及其团队在2006年的开创性论文中,提出了一种高效的分层无监督训练算法,用于训练一种叫做“深度信念网络(DBN)”的模型。
-
核心思想:“逐层预训练(Layer-wise Pre-training)”:先一层一层地、无监督地学习数据的底层特征(例如,先从像素中学习边缘,再从边缘学习轮廓,再从轮廓学习 parts),为整个网络提供一个良好的初始权重。
-
之后,再使用传统的反向传播算法进行微调(Fine-tuning)。
-
-
影响:这项工作打破了训练深层神经网络的壁垒,证明了深度网络可以有效地被训练,并在图像识别等任务上取得卓越性能。这一年被视为“深度学习复兴”的元年,为2012年AlexNet的爆发埋下了最直接的伏笔。
-
2.6.3. 承上启下
机器学习与数据驱动时期(1993-2010) 是AI发展史上一个至关重要的过渡和积累期:
-
它通过统计方法和大规模数据,解决了前两次寒冬中“脆弱”、“无法扩展”和“缺乏商业价值”的核心问题,使AI技术在搜索、推荐、广告、信用评分等领域创造了巨大价值。
-
然而,它依然严重依赖手工特征工程,这需要大量专业知识和人力,成为新的 “瓶颈”。研究者们开发了各种方法来从原始数据中手工提取有效的特征(如SIFT、HOG用于图像),再喂给机器学习模型。这一时期,模型的性能很大程度上依赖于特征工程的质量。
2.7. 深度学习与革命
- 时间:2010–至今
- 技术路线:循环神经网络模型(RNN、LSTM)、卷积神经网络(CNN)模型、Transformer 架构与大语言模型(LLM)
- 关键事件:
- 2012年,AlexNet 获得2012年ImageNet Challenge的冠军,并开启了深度学习元年。
- 2012年,人们才始重新审视并在所有序列任务上大规模应用 LSTM,使其在机器翻译、语音识别、文本生成等领域成为绝对主流
- 2017年,自注意力机制被提出,相比之前的 RNN 和 LSTM,Transformer具有极高的并行化能力(训练速度巨快)、无敌的建模能力(尤其擅长理解复杂语境)和强大的可扩展性(模型越大,性能越好)。
- 2018年,BERT 模型开启预训练时代。
- 2022年,ChatGPT 现象级应用,推动AI普及。
- 2023年,GPT-4、Claude、Gemini 等千亿级模型涌现。
- 深层原因:
- 算力指数级增长:TPU、A100 等专用芯片支撑万亿参数训练。
- 自监督学习:无需人工标注,从海量文本中自动学习。
- 商业闭环:AI产品(如 ChatGPT)直接变现,反哺研发。
2.7.1. 循环神经网络
RNN 和 LSTM 是深度学习革命前夜(尤其是在自然语言处理领域)最为关键的架构之一,它们都是为了解决一个核心问题:如何处理序列数据?如文本、语音、视频等,需要处理长序列数据。
循环神经网络 (Rucurrent Neural Network)的设计初衷是让网络能够记住之前看到过的信息,并利用这些信息来影响后续的输出。它通过在其内部结构中引入 “循环” 来实现这一点。在实际使用中,RNN 存在梯度消失/爆炸问题(Vanishing/Exploding Gradient),这是导致传统RNN难以处理长序列的根本原因。正因为RNN这个致命的缺陷,研究者们发明了它的增强版——LSTM。
长短期记忆网络(Long Short-Term Memory Network,LSTM)由 Sepp Hochreiter 和 Jürgen Schmidhuber 于 1997 年提出,是RNN的一个非凡变体,专门设计用来解决梯度消失问题。关键在于其精巧的“细胞状态(Cell State)”和三个“门(Gates)”结构,它们学会了有选择地记住或忘记信息。通过细胞状态和加性操作。误差在细胞状态上的反向传播几乎是无损的(因为主要是加法运算,梯度可以稳定传递),而不是像普通RNN那样是连续的乘法运算(导致梯度指数级缩小)。门控机制允许LSTM学会何时“忘记”历史信息、何时“记住”当前信息,从而极其精细地控制着信息的流动和记忆的时长。
LSTM成功地解决了长距离依赖问题,成为2018年Transformer出现之前,处理序列任务(尤其是机器翻译、文本生成、语音识别)的绝对霸主。它使得深度循环神经网络能够有效训练,并取得了前所未有的成功。Google翻译在相当长一段时间里使用的都是LSTM模型。
2.7.2. 卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)是深度学习领域最核心的架构,它通过卷积操作来处理图像数据,并使用卷积核来提取特征。
2.8. 通用人工智能
- 时间:未来
- 技术路线:多模态、自主进化、类脑计算
- 关键挑战:
- 认知架构:如何模拟人类“小样本学习”与“常识推理”?
- 伦理与风险:AI安全、价值对齐、社会影响。
- 深层原因:
- 技术极限:当前大模型仍依赖统计关联,缺乏因果推理。
- 需求升级:从 “工具” 转向 “伙伴”,需要跨领域泛化能力。
3. 人工智能的组成和结构
graph LR
AI[人工智能] --> ML[机器学习]
AI --> DL[深度学习]
AI --> NLP[自然语言处理]
AI --> CV[计算机视觉]
AI --> KR[知识表示与推理]
AI --> ROB[机器人学]
AI --> ES[专家系统]
AI --> RL[强化学习]
KR --> ONTO[本体论]
KR --> RULE[规则引擎]
KR --> LOGIC[逻辑系统]
KR --> KG[知识图谱]
KG --> EMB[知识嵌入]
KG --> RE[关系抽取]
KG --> KGQA[知识图谱问答]
ML --> SL[监督学习]
ML --> UL[无监督学习]
ML --> SSL[半监督学习]
ML --> TL[迁移学习]
DL --> CNN[卷积神经网络]
DL --> RNN[循环神经网络]
DL --> GAN[生成对抗网络]
DL --> TRANS[Transformer]
NLP --> SA[情感分析]
NLP --> MT[机器翻译]
NLP --> NER[命名实体识别]
NLP --> QA[问答系统]
CV --> IC[图像分类]
CV --> OD[目标检测]
CV --> IS[图像分割]
CV --> FR[人脸识别]
ROB --> NAV[自主导航]
ROB --> MAN[操作控制]
ROB --> HRI[人机交互]
ROB --> PER[环境感知]
ES --> KB[知识库]
ES --> INFER[推理机]
ES --> UI[用户界面]
ES --> EXPL[解释系统]
RL --> QL[Q-learning]
RL --> DRL[深度强化学习]
RL --> PG[策略梯度]
RL --> MARL[多智能体强化学习]
%% 三级节点详细展开
SL --> REG[线性回归]
SL --> CLA[逻辑回归]
SL --> DT[决策树]
SL --> SVM[支持向量机]
UL --> KMEANS[K-means聚类]
UL --> PCA[主成分分析]
UL --> DBSCAN[密度聚类]
UL --> AE[自编码器]
CNN --> RESNET[ResNet]
CNN --> VGG[VGG网络]
CNN --> YOLO[YOLO检测]
RNN --> LSTM[长短时记忆网络]
RNN --> GRU[门控循环单元]
RNN --> BPTT[随时间反向传播]
TRANS --> BERT[BERT模型]
TRANS --> GPT[GPT系列]
TRANS --> T5[T5文本转换]
OD --> RCNN[R-CNN系列]
OD --> SSD[SSD检测]
OD --> YOLOv8[YOLOv8]
NAV --> SLAM[SLAM建图]
NAV --> PATH[路径规划]
NAV --> LOC[定位技术]
QL[Q-learning]--> DQN[深度Q网络]
DRL --> DQN[深度Q网络]
DRL --> A3C[A3C算法]
DRL --> PPO[近端策略优化]
4. 人工智能的标志性成果
4.1. AlphaGo 等
AlphaGo 作为人工智能里程碑,首次在围棋领域击败人类职业选手,其核心创新在于深度融合深度学习、强化学习与蒙特卡洛树搜索(MCTS)算法。
围棋作为一种古老的策略游戏,其复杂的决策空间(约 $10^170$ 种可能局面)长期被视为人工智能领域的 “巨大挑战”。传统人工智能方法(如专家系统、暴力搜索)在处理围棋的复杂性时显得力不从心。2016年,Google DeepMind 开发的 AlphaGo 以 4:1 击败世界冠军李世石,标志着人工智能技术在复杂决策任务中取得了突破性进展。AlphaGo 的成功不仅在于其击败了人类选手,更在于它引入了一种新颖的方法论框架,融合了深度学习、强化学习和蒙特卡洛树搜索等多种技术,为后续人工智能研究奠定了坚实基础。
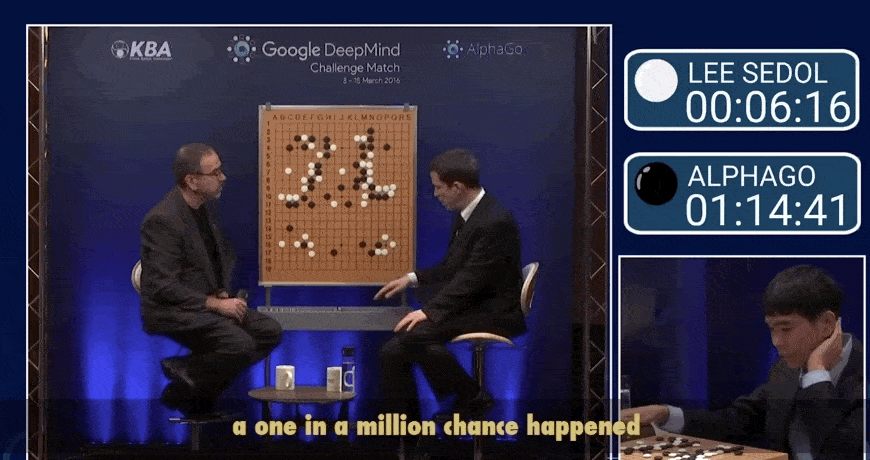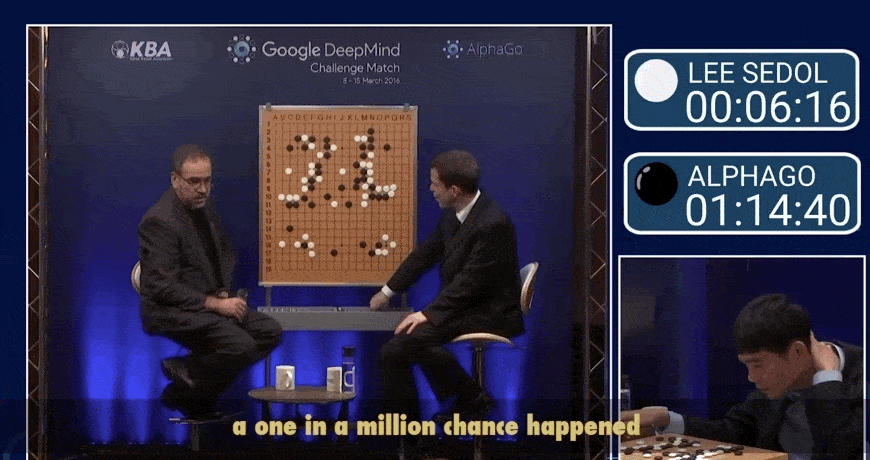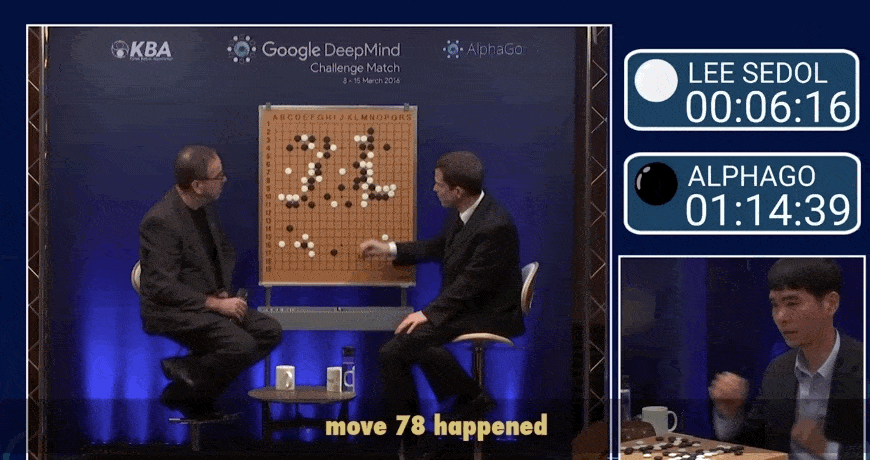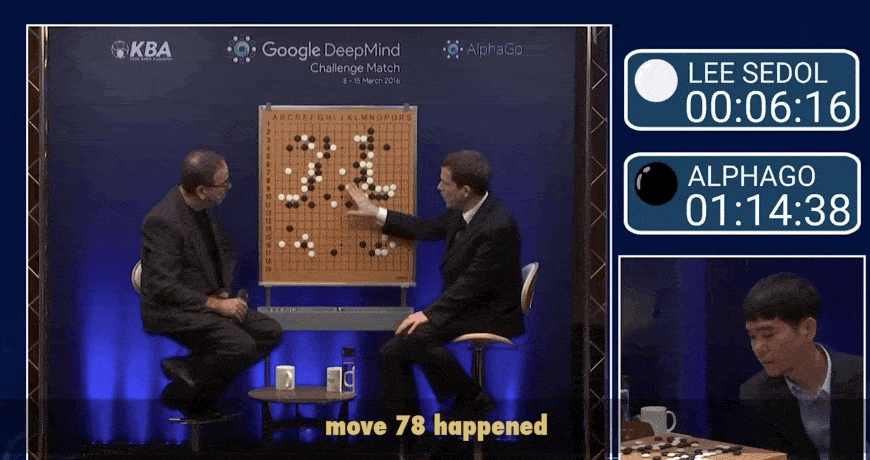
柯洁 VS AlphaGo Master. https://www.bilibili.com/video/BV1454y117ma/

AlphaGo 的技术核心在于解决了两个关键问题:局面评估(position evaluation)和搜索效率(search efficiency)。通过深度神经网络,AlphaGo 能够模仿人类棋手的直觉(策略网络)并评估局面优劣(价值网络),而蒙特卡洛树搜索则使系统能够高效探索可能的行为路径。这种架构设计使 AlphaGo 能够在不依赖暴力搜索的情况下,达到超越人类的决策水平。
AlphaGo 的系统功能由三个核心组件协同实现:策略网络(Policy Network)、价值网络(Value Network)和蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)。这三个组件共同构成了一个动态决策系统,能够在有限时间内做出近乎最优的决策。
4.1.1. 核心组件
4.1.1.1. 策略网络
策略网络是一个深度卷积神经网络(CNN),其作用是模拟人类棋手的”直觉”,根据当前棋盘状态预测下一步的最佳落子位置。该网络接收 $19\times 19$ 的棋盘状态作为输入(包括黑子、白子位置及历史信息),输出棋盘上每个合法落子点的概率分布。
AlphaGo 的策略网络实际上包含两个版本:监督学习策略网络(SL Policy Network)和强化学习策略网络(RL Policy Network)。监督学习版本通过分析约3000万个人类职业棋手棋谱数据进行训练,预测准确率达到57%。强化学习版本则通过自我对弈进一步优化,目标是最大化获胜概率而非模仿人类落子。
4.1.1.2. 价值网络
价值网络是另一个深度卷积神经网络,用于评估给定棋盘状态的胜率概率,输出一个介于 $-1$(绝对失败)到 $1$(绝对胜利)之间的标量值。与策略网络不同,价值网络的任务不是选择具体着法,而是预测当前玩家最终获胜的总体概率。
价值网络的训练数据来源于策略网络自我对弈产生的3000万局棋局。每个棋局的最终结果(胜/负)作为标签,训练价值网络预测棋局胜率。这种方法的挑战在于围棋局面极为复杂,需要避免过拟合,因为相似的局面可能导致完全不同的结果。
4.1.1.3. 蒙特卡洛树搜索
蒙特卡洛树搜索是 AlphaGo 的决策引擎,负责整合策略网络和价值网络的输出,进行前瞻性搜索以选择最优着法。传统 MCTS 在围棋中的应用受限于巨大的搜索空间,而 AlphaGo 通过神经网络引导的 MCTS 大幅提高了搜索效率。
4.1.2. 训练流程
4.1.2.1. 监督学习阶段
在监督学习阶段,AlphaGo 使用人类专家棋谱(KGS 棋服务器上的3000 万步着法)训练初始策略网络。该阶段的目标是让系统学习人类棋手的基本模式与直觉,快速建立基础棋力。通过监督学习训练的策略网络已经达到了业余棋手的水平,与之前最强的围棋AI相当。
4.1.2.2. 强化学习阶段
在强化学习阶段,AlphaGo 通过自我对弈进一步优化策略网络。系统使用策略梯度方法(如 REINFORCE 算法)调整网络参数,最大化预期胜率。在这个阶段,AlphaGo 与自身的不同版本对弈,生成大量训练数据,并不断改进策略。
4.1.2.3. 自我对弈与价值网络训练
在第三阶段,AlphaGo 通过自我对弈生成大量棋局数据(约 3000 万局),用于训练价值网络。这些数据涵盖了各种可能的局面类型,使价值网络能够准确预测不同局面的胜率。训练过程中,系统会精心挑选随机样本,以减少过拟合风险。
4.1.3. 演进与后续模型
4.1.3.1. AlphAGo Master
AlphaGo Master 是 AlphaGo 的升级版本,在 2017 年以 3:0 击败世界排名第一的柯洁九段,展示了更强大的棋力。该版本主要在前代基础上优化了网络结构和MCTS效率。
主要改进包括:
-
网络结构优化:使用更高效的卷积神经网络架构,减少了计算量同时提高了预测精度。
-
MCTS效率提升:优化了蒙特卡洛树搜索的选择策略,使搜索更加聚焦于高潜力着法。
-
训练过程改进:采用了更稳定的强化学习算法,减少了训练过程中的波动。
AlphaGo Master 的开发过程中,团队还发现了一个有趣现象:监督学习的策略网络表现优于强化学习的策略网络,这可能是因为人类棋手的着法更加多样化,而强化学习策略过于专注于最优着法。这一发现对后续研究提供了重要启示。
4.1.3.2. AlphGo Zero
AlphaGo Zero 是 AlphaGo 系列的重大飞跃,于2017年发布。与前辈不同,AlphaGo Zero 完全无需人类棋谱,仅通过自我对弈从随机参数开始学习,在 3 天内达到了超越 AlphaGo 的棋力。AlphaGo Zero 的棋风也与人类接受训练的版本有所不同,发现了许多新颖的着法和策略,这些着法后来被人类棋手研究和采用。这表明人工智能不仅可以模仿人类,还可以创造新知识。
AlphaGo Zero 的核心创新在于将策略网络和价值网络整合为一个双头神经网络(dual-headed network),共享大部分的卷积层。这种设计不仅减少了计算资源需求,还提高了训练效率。该统一网络接收当前棋盘状态作为输入,同时输出策略(概率分布)和价值(标量评估)。这种设计反映了围棋的一个基本特性:位置评估与最佳着法选择密切相关。
4.1.4. 讨论与挑战
-
可解释性
尽管AlphaGo系列取得了巨大成功,但这些系统仍面临着多项挑战和限制。AlphaGo 系列模型的一个主要挑战是可解释性不足。由于深度神经网络的 “黑盒” 特性,理解模型的具体决策过程仍然困难。例如,职业棋手有时难以理解AlphaGo的特定着法选择,尽管这些选择被证明是有效的。
-
计算资源需求
另外,AlphaGo 训练需要大量计算资源,这限制了资源有限的研究机构的访问。例如,最初的AlphaGo 使用了 1202 个 CPU 和 176 个 GPU,虽然后续版本计算效率提高,但资源需求仍然可观。
-
泛化能力
虽然AlphaZero展示了在多种游戏中的通用能力,但这些系统仍然局限于完全信息游戏。在处理不完全信息游戏(如扑克)或现实世界中的不确定环境时,仍然存在重大挑战。
4.2. ChatGPT 等
ChatGPT 通过融合大规模预训练语言模型与人类反馈强化学习(RLHF)技术,实现了自然、安全且有用的对话能力。
自然语言处理领域的对话系统长期面临着自然性、安全性和实用性的平衡挑战。传统的基于规则或检索的对话系统缺乏灵活性和生成能力,而早期的生成式模型往往产生不符合人类期望或含有有害内容的输出。
ChatGPT 的技术核心在于解决了对话系统的三个关键问题:对话一致性(contextual consistency)、安全性(safety)和人类偏好对齐(human preference alignment)。通过多阶段的训练流程,ChatGPT 能够产生不仅相关且连贯,而且符合人类价值观和偏好的回应。这种架构设计使ChatGPT在短短两个月内就吸引了超过 1 亿用户,成为历史上增长最快的消费者应用。
相关科普:https://www.bilibili.com/video/BV1yV4y1k7Tc/
4.2.1. 自注意力机制与 Transformer
自注意力机制(self-attention)是一种重要的模型组件,它允许模型在处理序列数据时,根据当前位置的输入信息,计算与当前位置相关的所有位置的权重,并生成一个表示当前位置的向量。
Transformer 是一种基于注意力机制的模型,它通过引入自注意力机制来处理序列数据。Transformer 模型在自然语言处理、计算机视觉、语音识别等领域都取得了显著进展。
4.2.2. GPT
GPT(Generative Pre-trained Transformer)是一个基于 Transformer 的模型,它被用于生成文本。
ChatGPT 的基础是 GPT 系列预训练语言模型,最初版本基于 GPT-3.5 架构,后续版本升级到 GPT-4。这些基础模型采用 Transformer 解码器架构,通过自回归方式预测下一个token 来生成文本 ChatGPT 的训练分为三个主要阶段:监督微调、奖励模型训练和强化学习优化。这种渐进式的训练策略使 ChatGPT 能够从简单的模仿学习逐步进阶到与复杂人类偏好对齐。