
本文介绍了统计学中的核回归方法,并铺垫了非参数化统计方法等一些基础知识。
1. 基本知识
1.1. 回归
回归分析(Regression Analysis)是一种统计学上分析数据的方法,目的在于了解两个或多个变量间是否相关、相关方向与强度,并建立数学模型以便观察特定变量来预测研究者感兴趣的变量。更具体的来说,回归分析可以帮助人们了解在只有一个自变量变化时因变量的变化量。一般来说,通过回归分析我们可以由给出的自变量估计因变量的条件期望。
回归分析是建立因变量 $Y$(或称依变量,反因变量)与自变量 $X$(或称独变量,解释变量)之间关系的模型。简单线性回归使用一个自变量 $X$,复回归使用超过一个自变量($X_{1},X_{2}…X_{i}$)。
-
参数回归
优点:
- 模型形式简单明确,仅由一些参数表达
- 在某些问题中,模型参数具有明确的含义(如经济问题中)
- 当模型参数假设成立时,统计推断的精度较高,能经受实际检验
- 模型能够进行外推运算
- 模型可以用于小样本的统计推断
缺点:
- 回归函数怒的形式需要预先假定
- 模型限制条件较多,一般要求样本满足某种分布,随机误差满足正态假设,解释变量间独立,解释变量与随机误差不相关等
- 模型泛化能力弱、缺乏稳健性
-
非参数回归
非参数回归是指并不需要知道总的分布的情况下进行的一种非参数统计方法。
非参数统计(nonparametric statistics),或称非参数统计学,统计学的分支,适用于母群体分布情况未明、小样本、母群体分布不为正态也不易变换为正态。特点在于尽量减少或不修改其建立之模型,较具稳健特性;在样本数不大时,计算过程较简单。
非参数统计推断时所使用的统计量的抽样分配通常与总体分配无关,不必推论其中位数、拟合优度、独立性、随机性,更广义的说,非参数统计又称为“不受分布限制统计法”(distribution free)。
优点:
- 回归函数形式自由、受约束少,对数据分布一般不做任何要求
- 适应能力强,稳健性高,回归模型完全由数据驱动
- 对于非线性、非齐次问题效果很好
缺点
- 不能进行外推运算
- 估计的收敛速度慢
- 一般只有在大样本下才能取得很好的效果,小样本效果较差
- 高维诅咒?
1.2. 近邻回归
1NN(1-Nearest Neighbor)回归:找寻与输入 $x_q$ 最接近的 $x_i$ 对应的 $y_i$ 作为预测输出。缺点时对大块区域没有数据或数据不足时敏感,拟合的不好。
KNN(K-Nearest Neighbor)回归:找寻 $k$ 个最近邻的点 $x_1,x_2,\cdots,x_k$,然后对他们对应的 $y_1,y_2,\cdots,y_k$ 求平均。
加权 kNN (Weighted K-Nearest Neighbor)回归:找寻 $k$ 个最近邻的点 $X_1,X_2,\cdots,X_k$,然后对他们对应的 $y_1,y_2,\cdots,y_k$ 求加权平均。权重取法为,离得更近的点具备更大的权重,反之更小。简单的算法为计算距离的倒数,即
\[\begin{aligned} y_{q} &= \frac{c_{1}y_{1}+\cdots+c_{k}y_{k}}{\sum_{j=1}^k c_{qj}}\\ c_{qj} &= \frac{1}{dis(x_j,x_q)} \end{aligned}\]影响近邻回归性能的因素:
-
k 如果 K 值选择的比较小,这时候我们就相当于使用较小的领域中的训练样本对实例进行预测。这时候,算法的近似误差会减小,因为只有与输入实例相近的训练样本才能才会对预测结果起作用。但是它也会有明显的缺点:算法的估计误差会偏大,预测的结果会对近邻点十分敏感,也就是说如果近邻点是噪声点的话,那么预测就会出错。也就是说,k 值太小会使得 KNN 算法容易过拟合。
同理,如果 K 值选的比较大的话,这时候距离较远的训练样本都能够对实例的预测结果产生影响。这时候,而模型相对比较鲁棒,不会因个别噪声点对最终的预测产生影响。但是缺点也是十分明显的:算法的近似误差会偏大,距离较远的点(与预测实例不相似)也会同样对预测结果产生作用,使得预测产生较大偏差。此时相当于模型发生欠拟合。
因此,在实际的工程实践过程中,我们一般采用交叉验证的方式选取 K 值。从上面的分析也可以知道,一般 k 值取得比较小。我们会选取 k 值在较小的范围,同时在测试集上准确率最高的那一个确定为最终的算法超参数 k。
-
距离度量方法
距离计算一般采用:
- 闵可夫斯基距离(欧氏距离、曼哈顿距离、切比雪夫距离)
- 余弦距离(余弦相似度)
闵可夫斯基距离不是一种距离,而是一类距离的定义。对于两个具有 $n$ 维特征的样本点 $\boldsymbol x_i,\boldsymbol x_q$,二者间的闵可夫斯基距离为
\[dis(\boldsymbol x_i,\boldsymbol x_q)=\left( \sum_{k=1}^n \vert x_i^k - x_q^k \vert^n \right)^{\frac{1}{n}}\]$p=1$ 时被称为曼哈顿距离; $p=2$ 时被称为欧氏距离(L2范数); $p\rightarrow \infty$ 时被称为切比雪夫距离。
对于两个具有 $n$ 维特征的样本点 $\boldsymbol x_i,\boldsymbol x_q$,二者间的余弦相似度为
\[sim_c(\boldsymbol x_i,\boldsymbol x_q) = cos(\boldsymbol x_i,\boldsymbol x_q)=\frac{\boldsymbol x_i\cdot \boldsymbol x_q}{\vert\vert\boldsymbol x_i\vert\vert\cdot\vert\vert\boldsymbol x_q\vert\vert} = \frac{\sum_{k=1}^n x_{ik}x_{qk}}{\sqrt{\sum_{k=1}^n x_{ik}^2} \sqrt{\sum_{k=1}^n x_{qk}^2}}\]则余弦距离为
\[dis_c(\boldsymbol x_i,\boldsymbol x_q) = 1 - sim_c(\boldsymbol x_i,\boldsymbol x_q)\]注意,余弦距离不是一个严格意义上的距离度量公式,但在形容两个特征向量之间的关系上用处很大。
当向量的模长经过归一化时,欧氏距离与余弦距离有着单调的关系
\[dis_2 = \sqrt{2\cdot dis_c}\]此时如果选择距离最小(相似度最大)的近邻,那么使用余弦相似度和欧氏距离的结果是相同的。
二者之间的使用差异如下:欧氏距离体现数值上的绝对差异,而余弦距离体现方向上的相对差异。
1) 例如,统计两部剧的用户观看行为,用户A的观看向量为(0,1),用户B为(1,0);此时二者的余弦距很大,而欧氏距离很小;我们分析两个用户对于不同视频的偏好,更关注相对差异,显然应当使用余弦距离。
2) 而当我们分析用户活跃度,以登陆次数(单位:次)和平均观看时长(单:分钟)作为特征时,余弦距离会认为(1,10)、(10,100)两个用户距离很近;但显然这两个用户活跃度是有着极大差异的,此时我们更关注数值绝对差异,应当使用欧氏距离。
1.3. 核回归
继续细化权重,提出核权重的概念。
\[c_{qj} = k(\boldsymbol x_i,\boldsymbol x_q)\]$k$ 是一个函数,一个二元函数,一个 $R^n\times R^n \rightarrow R^+$ 的二元函数,用来描述点与点之间的关系或者说距离的一种东西。
范数就是我们之前强调的距离,或者说广义的距离。向量空间中两向量的内积可度量其距离,即内积就是这个距离的定义的方式,也即由内积可以诱导出范数。可以用内积来刻画 kernel
\[k(\boldsymbol x_i,\boldsymbol x_q)=<\boldsymbol x_i,\boldsymbol x_q>\]根据不同的内积定义,可以构造出不同的核函数。
k 可以用原特征空间上点内积的方式经过运算转化成高维空间点内积的函数,可以用来避免在高维空间里进行繁琐的内积计算。
常用的高斯核如下
\[k_\lambda(x_i,x_q)=exp(-\frac{\vert\vert \boldsymbol x_i-\boldsymbol x_q\vert\vert^2}{\lambda})\]其它常用的核函数包括均匀分布核、三角核等等,如下图所示。
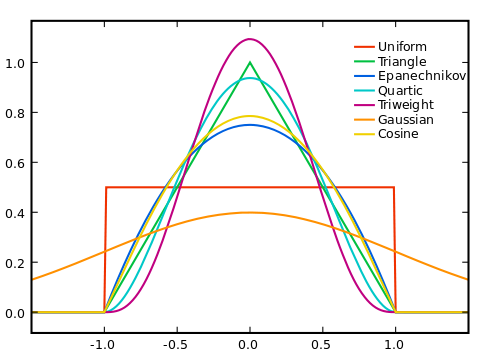
核回归就是升级版的加权 KNN,区别在于不是加权 k 个最近的邻居,而是加权所有样本点。然后权重是由特定的核函数来确定的。
\[y_q = \frac{\sum_{i=1}^N c_{qi}y_i}{\sum_{i=1}^Nc_{qi}} = \frac{\sum_{i=1}^N k_{\lambda}(\boldsymbol x_i,\boldsymbol x_q)y_i}{\sum_{i=1}^N k_{\lambda}(\boldsymbol x_i,\boldsymbol x_q)}\]要确定两个东西:
- 核
- $\lambda$
$\lambda$ 的选择根据验证集验证时的验证损失来确定。较小的 $\lambda$ 即使得预测量近受到附近距离很近的点的影响,过小的 $\lambda$ 会导致过拟合;过大的 $\lambda$ 则会导致过平滑,即欠拟合。
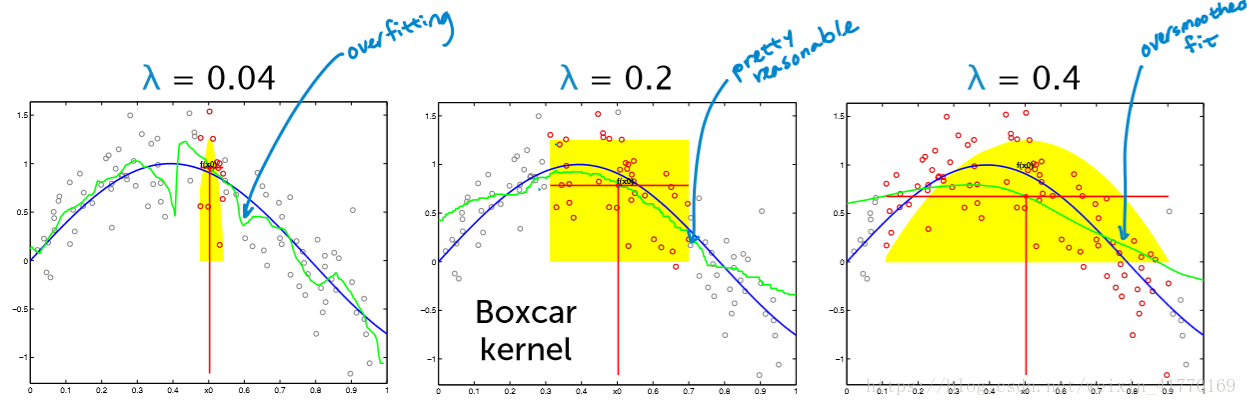
核的选择比 $\lambda$ 的选择更重要。很多时候我们根本不知道核函数将数据映射成了什么样子,映射后的可分离性可能更好,也可能更差。这个时候我们会尝试不同的核函数和参数。
对于非参数回归问题,点 $x_q$ 对应的预测值 $y_q$ 的条件期望可以写成某个未知函数 $m(\cdot)$ 与噪声 $\sigma$ 之和
\[y_q = \mathbb E(y\vert x=x_q)=m(x)+\sigma\]1964年,Nadaraya 和 Watson 提出了一种局部加权平均估计 $m(\cdot)$ 方法,称为 Nadaraya-Watson 核估计(或 Nadaraya-Watson 回归)。
\[y_q = \frac{\sum_{i=1}^N k_{\lambda}(\boldsymbol x_q-\boldsymbol x_i)y_i}{\sum_{i=1}^N k_{\lambda}(\boldsymbol x_q-\boldsymbol x_i)}\]另外两个核估计方法为 Priestley-Chao 核估计和 Gasser——Müller 核估计。
2. 参考文献
[1] 维基百科. Kernel regression