
Reptile 于2018年由 OpenAI 提出,是一种非常简单而有效的基于优化的(Optimized-based)小样本学习方法,通过多步梯度下降来学习一个较优的模型初始参数。
1. Reptile
2018.《On First-Order Meta-Learning Algorithms》和《Reptile: a Scalable Metalearning Algorithm》
Reptile是OpenAI提出的一种非常简单的meta learning 算法。与MAML类似,也是学习网络参数的初始值。
1.1. 算法
算法伪代码如下

其中,$\phi$ 是模型的初始参数,$\tau$ 是某个 task,$U_\tau^k(\phi)$ 表示从 $\phi$ 开始对损失函数进行 $k$ 次随机梯度下降,返回更新后的参数 $\widetilde{\phi}$。
在最后一步中,通过 $\widetilde{\phi}-\phi$ 这种残差形式来更新一次初始参数。
如果 $k=1$,该算法等价于「联合训练」(joint training,通过训练来最小化在一系列训练任务上期望损失)。
Reptile 要求 $k>1$,更新依赖于损失函数的高阶导数,此时 Reptile 的行为与 $k=1$(联合训练)时截然不同。
Reptile 与 MAML 和 FOMAML 紧密相关,但是也存在不同
-
Reptile 无需对每一个任务进行训练-测试(training-testing)划分。
-
相比 MAML 需要进行二重梯度计算,Reptile 只需要进行一重梯度计算,计算速度更快。
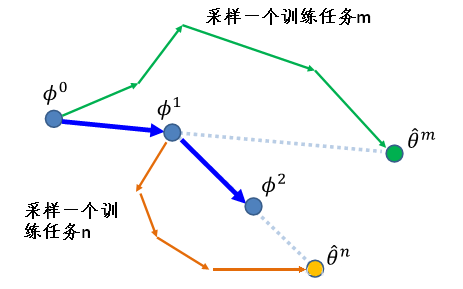
Reptile 的图例如下。
1.2. 数学分析
基于优化的元学习问题(Optimization-based Meta-Learning)的目标:找寻一组模型初始参数 $\boldsymbol \phi$,使得模型在面对随机选取的新任务 $\tau \sim \mathcal T$ 时,经过 $k$ 次梯度更新,在 $\tau$ 上的损失函数就能达到很小。
用数学语言描述,即
\[\mathop{minimize}_{\phi} \; \mathbb E_{\tau}[L_{\tau}(^{k}_\tau\boldsymbol \phi)] = \mathop{minimize}_{\phi} \; \mathbb E_{\tau}[L_{\tau}(U^k_\tau(\boldsymbol \phi))]\]其中
\[\widetilde{\boldsymbol\phi} = {}^{k}_\tau \boldsymbol \phi=U^k_\tau(\boldsymbol \phi)\]是在任务 $\tau$ 上经过 $k$ 次更新后的模型参数。
Reptile 算法中将 $(\boldsymbol \phi - \widetilde{\boldsymbol\phi}) / \alpha$ 看作梯度,其中 $\alpha$ 为 SGD 中的学习率,即
\[g_{Reptile} = (\boldsymbol \phi - \widetilde{\boldsymbol\phi}) / \alpha\]注意到,SGD 随机梯度下降的核心是,梯度是期望,期望可使用小规模的样本近似估计。
对于采用 SGD 的传统监督学习,模型参数更新方式为
\[\phi = \widetilde \phi = \phi - \beta \cdot \mathbb E[\nabla^kL_\tau] =? \phi - \beta \cdot \nabla^k\mathbb E[L_\tau]\]问题1:梯度和期望能否交换顺序?
传统监督学习的参数更新可简写为 $SGD(\mathbb E[L_\tau],\theta,k)$。
采用 SGD 的 Reptile 的模型参数更新方式为:
\[\phi = \phi + \beta\cdot \mathbb E[\widetilde\phi-\phi]/\alpha\]又因为 $\widetilde \phi = SGD(L_\tau,\theta,k)$,那么相应的参数更新可简写为 $\mathbb E[ SGD(L_\tau,\theta,k)]$。
问题2:$SGD(\mathbb E[L_\tau],\theta,k)$ 与 $\mathbb E[ SGD(L_\tau,\theta,k)]$ 有什么关系?
下面需要按照 $k$ 的取值分情况讨论。
- 如果 $k=1$,那么有
又知道,$U_\tau(\boldsymbol\phi)$ 是计算 $k=1$ 次的梯度算子(省略 $k$)
\[U_\tau(\boldsymbol\phi) = \boldsymbol \phi - \alpha \nabla_{\boldsymbol\phi} L_\tau(\boldsymbol\phi)\]则
\[\begin{aligned} \mathbb E_\tau [U_\tau(\boldsymbol \phi)] &= \mathbb E_\tau[\boldsymbol \phi - \alpha \nabla_{\boldsymbol\phi} L_\tau(\boldsymbol\phi)]\\ &= \boldsymbol\phi - \alpha \cdot \mathbb E_\tau [\nabla_{\boldsymbol\phi} L_\tau(\boldsymbol \phi)] \end{aligned}\]带入上式计算 $g_{Reptile,k=1}$,有
\[g_{Reptile,k=1} = \mathbb E_\tau[\nabla_{\boldsymbol\phi} L_\tau(\boldsymbol\phi)]\]因此有
\[g_{Reptile,k=1} = \mathbb E_\tau [(\boldsymbol \phi - \widetilde{\boldsymbol\phi}) / \alpha] = \mathbb E_\tau[\nabla_{\boldsymbol\phi} L_\tau(\boldsymbol\phi)]\]另外,根据此处的讨论,以及后续两处讨论,当损失函数足够光滑和有界时,期望和梯度可以交换顺序
The first step is probably the nastiest (although not in the discrete case I guess), but we can interchange the gradient and expectation assuming L is sufficiently smooth and bounded (which it probably is). See here(1) and here(2).
(1) When can we interchange the derivative with an expectation?
\[\mathbb E_{\tau\sim \mathcal T}[\nabla L_n(\phi)]=\nabla \mathbb E_{\tau\sim \mathcal T}[L_n(\phi)]\]那么
\[g_{Reptile,k=1} = \mathbb E_\tau [(\boldsymbol \phi - \widetilde{\boldsymbol\phi}) / \alpha] = \mathbb E_\tau[\nabla_{\boldsymbol\phi} L_\tau(\boldsymbol\phi)]= \nabla_{\boldsymbol\phi} \mathbb E_\tau[L_\tau(\boldsymbol\phi)]\]即 $k=1$ 时,Reptile 和 在期望损失 $\mathbb E_\tau [L_\tau]$ 上的联合训练 等价。
- 如果 $k>1$,那么
而
\[U_{\phi}^k(\boldsymbol\phi) = \boldsymbol \phi- \alpha \boldsymbol g_1- \alpha \boldsymbol g_2-...- \alpha \boldsymbol g_k\]其中
\[\begin{aligned} \boldsymbol g_1 & = \nabla_{\boldsymbol \theta} L_\tau(\boldsymbol \theta), \quad {}^1\boldsymbol \theta = \boldsymbol \theta - \alpha \boldsymbol g_1\\ \boldsymbol g_2 & = \nabla_{ {}^1\boldsymbol \theta} L_\tau({}^1\boldsymbol \theta)\\ &= \nabla_{ {}^1\boldsymbol \theta} L_\tau(\boldsymbol \theta - \alpha \boldsymbol g_1)\\ &= \nabla_{ {}^1\boldsymbol \theta} L_\tau(\boldsymbol \theta - \alpha (\nabla_{\boldsymbol \theta} L_\tau(\boldsymbol \theta)))\\ ...&... \end{aligned}\]$\mathbb E_\tau [U_{\phi}^k(\boldsymbol\phi)]$ 中包含了高阶项信息,从而与 $\nabla \mathbb E[L_\tau]$ 不再相关。此时 Reptile 收敛到的参数解与传统监督学习完全不同。
1.3. 梯度的泰勒展开的领头阶
那么,为什么Reptile就这么简单的多更新几步梯度( k>1 )就能很好的进行元学习呢?作者通过泰勒展开的领头阶来分析。
首先定义四个辅助变量,假设模型初始参数为 $\phi_1$,$i\in [1, k]$ 指代第 $i$ 次梯度下降的训练过程:
\[\begin{aligned} g_i &= L_i'(\phi_i) \;\;(gradient \; obtained\; during\;SGD)\\ \phi_{i+1} &= \phi_i-\alpha g_i \;\;(sequence\;of\;parameters)\\ \overline{g}_i &= L_i'(\phi_1) \;\;(gradient\;at\;initial\;point)\\ \overline{H}_i &= L_i''(\phi_1) \;\;(Hessian\;at\;initial\;point)\\ \end{aligned}\]然后将 $g_i$ 在原始参数 $\phi_1$ 上泰勒展开至 “二阶导+高次项” 的形式
\[\begin{aligned} g_i = L_i'(\phi_i) &= L_i'(\phi_1) + L_i''(\phi_1)(\phi_i - \phi_1) + O(||\phi_i - \phi_1||^2)\\ &= \overline{g}_i + \overline{H}_i(\phi_i - \phi_1) + O(\alpha^2)\\ &= \overline{g}_i - \alpha\overline{H}_i\sum_{j=1}^{i-1}g_j + O(\alpha^2)\\ &= \overline{g}_i - \alpha\overline{H}_i\sum_{j=1}^{i-1}\overline{g}_j + O(\alpha^2)\\ \end{aligned}\]下面分析上式的推导过程。根据第二个辅助变量的定义,进行链式展开,高阶项的推导过程如下
\[\begin{aligned} &\phi_i = \phi_1 - \alpha g_1 - \alpha g_2 - ... - \alpha g_{i-1}\\ \Rightarrow \quad &O(||\phi_i - \phi_1||^2) = O(|| - \alpha \sum_{j=1}^{i-1} g_j||^2) = O(\alpha^2) \end{aligned}\]同理,第二个等号右边,Hessian 矩阵右乘的括号和可化为 $g_i$ 的和形式。
最后一个等号右边,可以直接将 $g_i$ 替换为 $\overline g_i$ 是因为
\[\begin{aligned} \alpha\overline{H}_i\sum_0^{i-1}g_i &= \alpha\overline{H}_i\sum_0^{i-1}L_i'(\phi_i) \\ &= \alpha\overline{H}_i\sum_0^{i-1}[L_i'(\phi_1) + L_i''(\phi_1)(\phi_i - \phi_1)+O(\alpha^2)]\\ &=\alpha\overline{H}_i\sum_0^{i-1}[\overline g_i- \alpha\overline{H}_i\sum_{j=1}^{i-1}g_j + O(\alpha^2)]\\ &= \alpha\overline{H}_i\sum_0^{i-1}\overline g_i + O(\alpha^2) \end{aligned}\]至此,我们可以得到$g_i$ 在原始参数 $\phi_1$ 上的泰勒展开如下
\[g_i = \overline{g}_i - \alpha\overline{H}_i\sum_{j=1}^{i-1}\overline{g}_j + O(\alpha^2)\]然后,我们对 $g_{MAML}$ 进行分析
\[\begin{aligned} g_{MAML} &= \frac{\partial}{\partial\phi_1}L_k(\phi_k)\\ &= L'_k(\phi_k)\frac{\partial\phi_k}{\partial\phi_1}\\ &= L'_k(\phi_k)\frac{\partial}{\partial\phi_1}[U_{k-1}(U_{k-2}(...(U_1(\phi_1))))]\\ &= L'_k(\phi_k)U'_1(\phi_1)U'_2(\phi_2)\cdots U'_{k-1}(\phi_{k-1})\\ &= L'_k(\phi_k)(I-\alpha L''_1(\phi_1))\cdots(I-\alpha L''_{k-1}(\phi_{k-1}))\\ &=L'_k(\phi_k)\left(\prod_{i=1}^{k-1}(I-\alpha L''_i(\phi_i))\right)\\ &=g_k\left(\prod_{i=1}^{k-1}(I-\alpha L''_i(\phi_i))\right) \end{aligned}\]此处,令 $\alpha=0^+$,我们可以给出 $g_{FOMAML}$ 的表达式
\[g_{FOMAML} = g_k\]根据前面已经推得的 $g_i$ 在原始参数上的泰勒展开式,带入得
\[g_{FOMAML} = \overline{g}_k - \alpha\overline{H}_k\sum_{j=1}^{k-1}\overline{g}_j + O(\alpha^2)\]继续推导 $g_{MAML}$,借助第四个辅助变量定义,我们对 $\alpha L’‘_i(\phi_i)$ 在原始参数上进行泰勒展开
\[\begin{aligned} \alpha L''_i(\phi_i) &= \alpha L''_i(\phi_1) + \alpha H'_i(\phi_1 - \phi_1) + O(\alpha^2) \\ &= \alpha \overline H_i + \alpha H'_i\sum \alpha g_{i-1} + O(\alpha^2)\\ &= \alpha \overline H_i + O(\alpha^2) \end{aligned}\]带入 $g_{MAML}$,有
\[g_{MAML} = g_k\left(\prod_{i=1}^{k-1}(I-\alpha \overline H_i)\right) + O(\alpha^2)\]又根据前面已经推得的 $g_i$ 在原始参数上的泰勒展开式,带入得
\[\begin{aligned} g_{MAML} &= \left(\overline{g}_k - \alpha\overline{H}_k\sum_{j=1}^{k-1}\overline{g}_j\right) \left( \prod_{i=1}^{k-1}(I-\alpha \overline H_i)\right) + O(\alpha^2)\\ &= \left(\overline{g}_k - \alpha\overline{H}_k\sum_{j=1}^{k-1}\overline{g}_j\right) [ (I-\alpha \overline H_1)\cdots(I-\alpha \overline H_{k-1}) ] + O(\alpha^2)\\ &= \left(\overline{g}_k - \alpha\overline{H}_k\sum_{j=1}^{k-1}\overline{g}_j\right) [I-\alpha \overline H_1 - \cdots - \alpha \overline H_{k-1} + O(\alpha^2)] + O(\alpha^2)\\ &= \left(\overline{g}_k - \alpha\overline{H}_k\sum_{j=1}^{k-1}\overline{g}_j\right) \left(I-\alpha \sum_{j=1}^{k-1}\overline H_j\right) + O(\alpha^2)\\ &= \overline{g}_k - \alpha\overline{g}_k\sum_{j=1}^{k-1}\overline H_j - \alpha\overline{H}_k\sum_{j=1}^{k-1}\overline{g}_j + O(\alpha^2) \end{aligned}\]而对于 Reptile 的梯度,根据定义
\[\begin{aligned} g_{Reptile} &= (\phi - \widetilde \phi)/\alpha\\ &= [\phi - (\phi - \alpha g_1 - \alpha g_2 - \cdots - \alpha g_k)]/\alpha\\ &= g_1 + g_2 + \cdots + g_k \end{aligned}\]将 MAML、FOMAML 和 Reptile 三者的梯度同时列写如下
\[\begin{aligned} g_{MAML} &=\overline{g}_k - \alpha\overline{g}_k\sum_{j=1}^{k-1}\overline H_j - \alpha\overline{H}_k\sum_{j=1}^{k-1}\overline{g}_j + O(\alpha^2)\\ g_{FOMAML} &= \overline{g}_k - \alpha\overline{H}_k\sum_{j=1}^{k-1}\overline{g}_j + O(\alpha^2)\\ g_{Reptile} &= g_1 + g_2 + \cdots + g_k \end{aligned}\]为了简化分析,令 $k=2$,有
\[\begin{aligned} g_{MAML} & &=\overline{g}_2 - \alpha\overline{g}_2\overline H_1 - \alpha\overline{H}_2\overline{g}_1 + O(\alpha^2)\\ g_{FOMAML} &= g_2 &= \overline{g}_2 - \alpha\overline{H}_2\overline{g}_1 + O(\alpha^2)\\ g_{Reptile} &= g_1 + g_2 &=\overline{g}_1 + \overline{g}_2 - \alpha\overline{H}_2 g_1 + O(\alpha^2) \end{aligned}\]1.4. 另一种推导方式
直接假设 $k=2$,以两步 SGD 为例分析参数更新过程。
简化起见,我们将损失函数对模型参数的梯度记为 $L’$,那么两步 SGD 更新后的模型参数为 $\phi_3$,有
\[\begin{aligned} \phi_1 &= \phi\\ \phi_2 &= \phi_1 - \alpha L_1'(\phi_1)\\ \phi_3 &= \phi_2 - \alpha L_1'(\phi_1) - \alpha L_2'(\phi_2) \end{aligned}\]下面定义几个辅助变量,其中 $i\in [1, k]$ 指代第 $i$ 个 minibatch,也即第 $i$ 次梯度下降的训练过程(?)
\[\begin{aligned} g_i &= L_i'(\phi_i) \;\;(gradient \; obtained\; during\;SGD)\\ \phi_{i+1} &= \phi_i-\alpha g_i \;\;(sequence\;of\;parameters)\\ \overline{g}_i &= L_i'(\phi_1) \;\;(gradient\;at\;initial\;point)\\ \overline{H}_i &= L_i''(\phi_1) \;\;(Hessian\;at\;initial\;point)\\ \end{aligned}\]首先,采用泰勒展开将 $g_i$ 展开至 “二阶导+高次项” 的形式
\[\begin{aligned} g_i &= L_i'(\phi_i) = L_i'(\phi_1) + L_i''(\phi_1)(\phi_i - \phi_1) + O(||\phi_i - \phi_1||^2)\\ &= \overline{g}_i + \overline{H}_i(\phi_i - \phi_1) + O(\alpha^2)\\ &= \overline{g}_i - \alpha\overline{H}_i\sum_0^{i-1}g_i + O(\alpha^2)\\ &= \overline{g}_i - \alpha\overline{H}_i\sum_0^{i-1}\overline{g}_i + O(\alpha^2)\\ \end{aligned}\]最后一步的依据是,$g_i = \overline{g}_i + O(\alpha)$ 带入倒数第二行时,后面的 $O(\alpha)$ 与求和符号前的 $\alpha$ 相乘,即变为 $O(\alpha^2)$ 从而合并为一项。
下面取 $k=2$ ,即两步SGD,分别推导 MAML、FOMAML、Reptile 的梯度。这个参考 [3] 考虑了 $k$ 为任意情况下的通解,在 $k=2$ 时的结果与本文相同。
对于二阶的MAML,初始参数 $\phi_1$ 首先在support set上梯度更新一次得到 $\phi_2$ ,然后将 $\phi_2$ 在 query set 上计算损失函数,再计算梯度更新模型的初始参数。即 query set 的 loss 要对 $\phi_2$ 求导,链式法则 loss 对 $\phi_2$ 求导乘以 $\phi_2$ 对 $\phi_1$ 求导
\[\begin{aligned} g_{MAML} &= \frac{\partial}{\partial\phi_1}L_2(\phi_2) = \frac{\partial \phi_2}{\partial \phi_1} L_2'(\phi_2) \\ &= (I-\alpha L_1''(\phi_1))L_2'(\phi_2)\\ &= (I-\alpha L_1''(\phi_1))(L_2'(\phi_1) + L_2''(\phi_1)(\phi_2 - \phi_1) + O(\alpha^2))\\ &= (I-\alpha L_1''(\phi_1))(L_2'(\phi_1) + L_2''(\phi_1)(\phi_2 - \phi_1)) + O(\alpha^2)\\ &= (I-\alpha L_1''(\phi_1))(L_2'(\phi_1) - \alpha L_2''(\phi_1)L_1'(\phi_1)) + O(\alpha^2)\\ &= L_2'(\phi_1)-\alpha L_2''(\phi_1)L_1'(\phi_1) - \alpha L_1''(\phi_1)L_2'(\phi_1) + O(\alpha^2)\\ \end{aligned}\]对于FOMAML,其一阶简化是简化了参数 $\phi_2$ 对初始参数 $\phi_1$ 求导部分,即 $\frac{\partial \phi_2}{\partial \phi_1} = const$,则只剩下 loss 对参数 $\phi_2$ 的求导。
\[\begin{aligned} g_{FOMAML} &= L_2'(\phi_2) = L_2'(\phi_1) + L_2''(\phi_1)(\phi_2 - \phi_1) + O(\alpha^2)\\ &= L_2'(\phi_1) -\alpha L_2''(\phi_1)L_1'(\phi_1) + O(\alpha^2) \end{aligned}\]对于Reptile,根据梯度定义和SGD过程有
\[\begin{aligned} g_{Reptile} &= (\phi_1 - \phi_3)/\alpha = L_1'(\phi_1)+L_2'(\phi_2)\\ &= L_1'(\phi_1)+L_2'(\phi_1)+ L_2''(\phi_1)(\phi_2-\phi_1) + O(\alpha^2)\\ &= L_1'(\phi_1)+L_2'(\phi_1)-\alpha L_2''(\phi_1)L_1'(\phi_1) + O(\alpha^2) \end{aligned}\]接下来对上面的三个梯度进行变量替换,全部用之前定义的辅助变量来表示
\[\begin{aligned} g_{MAML} & &= \overline{g}_2 - \alpha \overline{H_2}\overline{g}_1-\alpha\overline{H_1}\overline{g}_2+O(\alpha^2)\\ g_{FOMAML} &= g_2 &= \overline{g}_2-\alpha\overline{H}_2\overline{g}_1+O(\alpha^2)\\ g_{Reptile} &= g_1+g_2 &= \overline{g}_1+\overline{g}_2-\alpha \overline{H}_2\overline{g}_1 + O(\alpha^2)\\ \end{aligned}\]可以得到与上一节一致的结果。
1.5. 梯度的泰勒展开的领头阶(继续)
再次定义两个期望参数如下。
第一个:AvgGrad 定义为loss对初始参数的梯度的平均期望
\[AvgGrad = \mathbb E_{\tau,1}[\overline{g}_1] =\mathbb E_{\tau,2}[\overline{g}_2]\](-AvgGrad)是参数 $\phi$ 在最小化 joint training 问题中的下降方向。就是想在所有batch上减小loss,也就是减小整体的任务损失。
为什么此处 $\overline{g}_1$ 和 $\overline{g}_2$ 的期望相等呢,因为它们都是表示的是loss对原始参数的梯度,只不过对应于不同的batch。在minibatch中,一个batch用于进行一次梯度下降,因为batch是随机的,所以loss对原始参数的梯度与batch是无关的。
第二个:AvgGradInner
\[\begin{aligned} AvgGradInner &= \mathbb E_{\tau,1,2}[\overline{H}_1\overline{g}_2]\\ &= \mathbb E_{\tau,1,2}[\overline{H}_2\overline{g}_1]\\ &= \frac{1}{2}\mathbb E_{\tau,1,2}[\overline{H}_1\overline{g}_2+\overline{H}_2\overline{g}_1]\\ &= \frac{1}{2}\mathbb E_{\tau,1,2}[\frac{\partial}{\partial \phi_1}(\overline{g}_1\cdot \overline{g}_2)] \end{aligned}\](-AvgGradInner) 的方向可以增大不同minibatch间梯度的内积,从而提高泛化能力。换句话说,AvgGradInner是 $\overline{g}_0\overline{g}_1$ 的对原始参数的导数,因为梯度在参数更新时是加负号的,所以是在最大化同一任务中不同minibatch之间梯度的内积。对其中一个batch进行梯度更新会显著改善另一个batch的的表现,这样就增加了模型的泛化性和快速学习的能力。
下面就可以对上述三个梯度进行进一步替换,$k=2$ 时
\[\begin{aligned} \mathbb{E}[g_{MAML}] &= (1)AvgGrad - (2\alpha)AvgGradInner + O(\alpha^2)\\ \mathbb{E}[g_{FOMAML}] &= (1)AvgGrad - (\alpha)AvgGradInner + O(\alpha^2)\\ \mathbb{E}[g_{Reptile}] &= (2)AvgGrad - (\alpha)AvgGradInner + O(\alpha^2)\\ \end{aligned}\]扩展到 $k>2$ 的情况有 [3]
\[\begin{aligned} \mathbb{E}[g_{MAML}] &= (1)AvgGrad - (2(k-1)\alpha)AvgGradInner + O(\alpha^2)\\ \mathbb{E}[g_{FOMAML}] &= (1)AvgGrad - ((k-1)\alpha)AvgGradInner + O(\alpha^2)\\ \mathbb{E}[g_{Reptile}] &= (2)AvgGrad - (\frac{1}{2}k(k-1)\alpha)AvgGradInner + O(\alpha^2)\\ \end{aligned}\]可以看到三者AvgGradInner与AvgGrad之间的系数比的关系是:MAML > FOMAML > Retile。这个比例与步长 $\alpha$,迭代次数 $k$ 正相关。
综上所述, MAML 和 Reptile 的优化目标相同,都是更好的任务表现(由 AvgGrad 主导)和更好的泛化能力(由 AvgGradInner 主导)。
1.6. 另一种不严谨的分析
另一种分析有效的方法借助了流形,Reptile 收敛于一个解,这个解在欧式空间上与每个任务的最优解的流形接近。没看懂不管了。作者自己也号称不如泰勒展开严谨。
This is a informal argument and should be taken much less seriously than the preceding Taylor series analysis
1.7. 实验
少样本分类
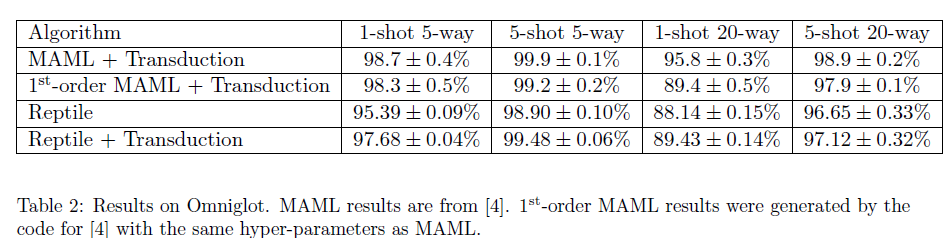
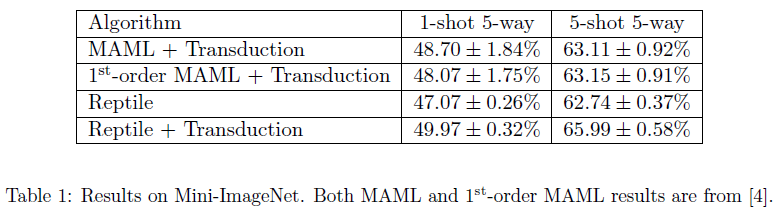
从两个表格中的数据可以看出,MAML与Reptile在加入了转导(Transduction)后,在Mini-ImageNet上进行实验,Reptile的表现要更好一些,而Omniglot数据集上正好相反。
不同的内循环梯度组合比较
通过在内循环中使用四个不重合的Mini-Batch,产生梯度数据 g1,g2,g3,g4 ,然后将它们以不同的方式进行线性组合(等价于执行多次梯度更新)用于外部循环的更新,进而比较它们之间的性能表现,实验结果如下图:
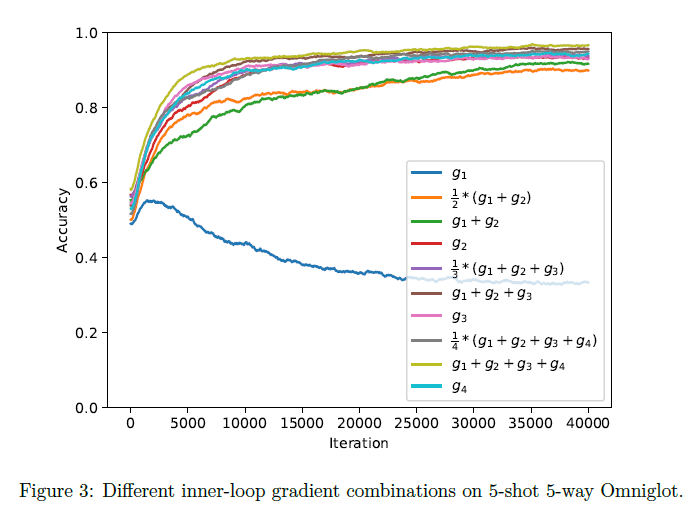
从曲线可以看出:
- 仅使用一个批次的数据产生的梯度的效果并不显著,因为相当于让模型用见到过的少量的数据去优化所有任务。
- 进行了两步更新的Reptile(绿线)的效果要明显不如进行了两步更新的FOMAML(红线),因为Reptile在AvgGradInner上的权重(AvgGradInner与AvgGrad的系数的比例)要小于FOMAML。
- 随着mini-batch数量的增多,所有算法的性能也在提升。通过同时利用多步的梯度更新,Reptile的表现要比仅使用最后一步梯度更新的FOMAML的表现好。
内循环中Mini-Batch 重合比较
Reptile和FOMAML在内循环过程中都是使用的SGD进行的优化,在这个优化过程中任何微小的变化都将导致最终模型性能的巨大变化,因此这部分的实验主要是探究两者对于内循环中的超数的敏感性,同时也验证了FOMAML在minibatch以错误的方式选取时会出现显著的性能下降情况。
mini-batch的选择有两种方式:
- shared-tail(共尾):最后一个内循环的数据来自以前内循环批次的数据
- separate-tail(分尾):最后一个内循环的数据与以前内循环批次的数据不同
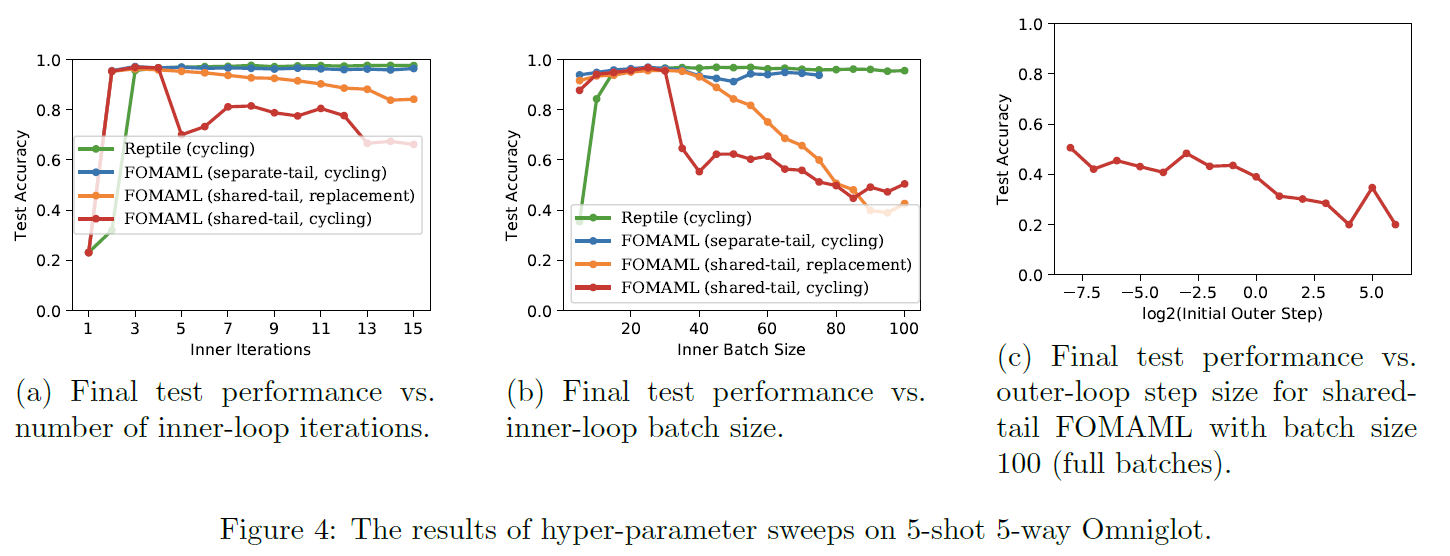
采用不同的mini-batch选取方式在FOMAML上进行实验,发现随着内循环迭代次数的增多,采用分尾方式的FOMAML模型的测试准确率要高一些,因为在这种情况下,测试的数据选取方式与训练过程中的数据选取方式更为接近。
当采用不同的批次大小时,采用共尾方式选取数据的FOMAML的准确性会随着批次大小的增加而显著减小。当采用full-batch时,共尾FOMAML的表现会随着外循环步长的加大而变差。
共尾FOMAML的表现如此敏感的原因可能是最初的几次SGD更新让模型达到了局部最优,以后的梯度更新就会使参数在这个局部最优附近波动。
2. 比较
再次比较Model Pre-training、MAML 和 Reptile方法。
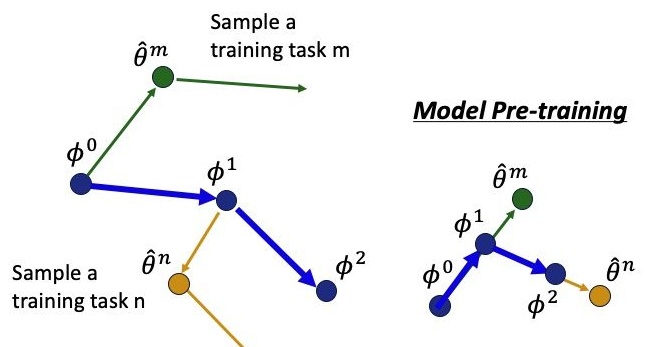
(左:MAML。右:Model Pre-training)
(Reptile)
Pre-training采用task的loss对参数的梯度更新模型的原始参数。
MAML采用task的第二次梯度计算更新模型的原始参数。
Reptile采用多次梯度计算更新模型的原始参数。
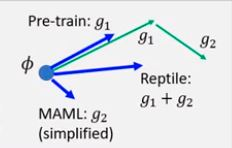
上面这个图不具体,但是很直观的展示了这些算法的区别。$g_i$ 表示第 $i$ 次负梯度计算。这里的MAML是一阶的,沿着 $g_2$ 方向更新,Reptile 沿着 $g_1+g_2$ 的方向更新,而我们常规的预训练模型就是沿着 $g_1$ 方向更新。
3. 算法实现
First-order近似实现Reptile:https://github.com/dragen1860/Reptile-Pytorch
4. reptile回归sin函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
import numpy as np
import torch
from torch import nn, autograd as ag
import matplotlib.pyplot as plt
from copy import deepcopy
seed = 0
plot = True
innerstepsize = 0.02 # stepsize in inner SGD
innerepochs = 1 # number of epochs of each inner SGD
outerstepsize0 = 0.1 # stepsize of outer optimization, i.e., meta-optimization
niterations = 30000 # number of outer updates; each iteration we sample one task and update on it
rng = np.random.RandomState(seed)
torch.manual_seed(seed)
# Define task distribution
x_all = np.linspace(-5, 5, 50)[:,None] # generate 50 x points within [-5,5]
ntrain = 10 # Size of training minibatches
def gen_task():
"Generate regression problem"
phase = rng.uniform(low=0, high=2*np.pi)
ampl = rng.uniform(0.1, 5)
f_randomsine = lambda x : np.sin(x + phase) * ampl
return f_randomsine
# Define model. Reptile paper uses ReLU, but Tanh gives slightly better results
model = nn.Sequential(
nn.Linear(1, 64),
nn.Tanh(),
nn.Linear(64, 64),
nn.Tanh(),
nn.Linear(64, 1),
)
def totorch(x):
return ag.Variable(torch.Tensor(x))
def train_on_batch(x, y):
x = totorch(x)
y = totorch(y)
model.zero_grad()
ypred = model(x)
loss = (ypred - y).pow(2).mean()
loss.backward()
for param in model.parameters():
param.data -= innerstepsize * param.grad.data
def predict(x):
x = totorch(x)
return model(x).data.numpy()
# Choose a fixed task and minibatch for visualization
f_plot = gen_task()
xtrain_plot = x_all[rng.choice(len(x_all), size=ntrain)]
# Reptile training loop
for iteration in range(niterations): # iterate 30000 times
weights_before = deepcopy(model.state_dict())
# Generate task
f = gen_task()
y_all = f(x_all)
# Do SGD on this task
inds = rng.permutation(len(x_all)) # get random index of 0-50
for _ in range(innerepochs): # SGD 1 times
for start in range(0, len(x_all), ntrain): # from 0-50, select a num every 'ntrain' interval
mbinds = inds[start:start+ntrain] # get randomly index from 'start' to 'ntrain'
train_on_batch(x_all[mbinds], y_all[mbinds])
# Interpolate between current weights and trained weights from this task
# I.e. (weights_before - weights_after) is the meta-gradient
weights_after = model.state_dict()
outerstepsize = outerstepsize0 * (1 - iteration / niterations) # linear schedule
model.load_state_dict({name :
weights_before[name] + (weights_after[name] - weights_before[name]) * outerstepsize
for name in weights_before})
# Periodically plot the results on a particular task and minibatch
if plot and iteration==0 or (iteration+1) % 1000 == 0:
plt.cla()
f = f_plot
weights_before = deepcopy(model.state_dict()) # save snapshot before evaluation
plt.plot(x_all, predict(x_all), label="pred after 0", color=(0,0,1))
for inneriter in range(32):
train_on_batch(xtrain_plot, f(xtrain_plot))
if (inneriter+1) % 8 == 0:
frac = (inneriter+1) / 32
plt.plot(x_all, predict(x_all), label="pred after %i"%(inneriter+1), color=(frac, 0, 1-frac))
plt.plot(x_all, f(x_all), label="true", color=(0,1,0))
lossval = np.square(predict(x_all) - f(x_all)).mean()
plt.plot(xtrain_plot, f(xtrain_plot), "x", label="train", color="k")
plt.ylim(-4,4)
plt.legend(loc="lower right")
plt.pause(0.01)
model.load_state_dict(weights_before) # restore from snapshot
print(f"-----------------------------")
print(f"iteration {iteration+1}")
print(f"loss on plotted curve {lossval:.3f}") # optimized in one example for brevity
- 用 $sin$ 函数来测试Reptile算法。
- 在 $[-5,5]$ 区间内随机取50个$x$点
- 在 $[0,2\pi]$ 区间内随机取相位$P$
- 在 $[0.1,5]$ 区间内随机取幅值$A$
-
那么就可以随机生成任意相位幅值的50个点的sin函数:$Asin(x+P)$
- 设置minibatch的个数为ntrain=10,也就是一次训练10个点
-
先随机产生一个 $sin$ 函数,并在其上随机取10个点,作为测试集
- 进行外环迭代 niterations=30000次
- 随机产生一个 $sin$ 函数
- 进行内环迭代innerepochs=1次
- 随机取50个点($x$)中的10个点(ntrain)
- 训练一次(SGD)
- 取5次直到取完所有50个点
- [完成内环迭代]
- 更新外层学习率 outerstepsize = outerstepsize0 * (1 - iteration / niterations)
- 更新模型参数 weights_before+ (weights_after - weights_before) * outerstepsize
- 若外环迭代达到1000次的整数倍,那么将训练的模型在测试集上测试
- 测试迭代inneriter=32次
- 在测试集上训练一次(10个离散点)
- 每过8次画一次图上的曲线(50个离散点)
- MSE衡量测试结果
- [完成外环迭代]
5. 参考文献
[1] Rust-in. MAML 论文及代码阅读笔记.
[2] 人工智障. MAML算法,model-agnostic metalearnings?