
小样本学习(Few-Shot Learning)问题是一个新兴的机器学习问题,旨在研究当样本个数严重不足时,如何训练一个模型,能够快速的完成学习(分类、回归、强化学习等)任务。进一步引入元学习的思想来解决小样本学习问题。
1. 小样本学习问题
Few-Shot Learning (FSL)
众所周知,现在的主流的传统深度学习技术需要大量的数据来训练一个好的模型。例如典型的 MNIST 分类问题,一共有 10 个类(“0”~“9”,一共10类数字),训练集一共有 6000 个样本,平均下来每个类大约 600 个样本。

但是我们想一下我们人类自己,我们区分 0 到 9 的数字图片的时候需要看 6000 张图片才知道怎么区分吗?很显然,不需要!这表明当前的深度学习技术和我们人类智能差距还是很大的,要想弥补这一差距,少样本学习是一个很关键的问题。
另外还有一个重要原因是如果想要构建新的数据集,还是举分类数据集为例,我们需要标记大量的数据,但是有的时候标记数据集需要某些领域的专家(例如医学图像的标记),这费时又费力,因此如果我们可以解决FSL问题,只需要每个类标记几张图片就可以高准确率的给剩余大量图片自动标记。这两方面的原因都让FSL问题很吸引人。
总结一下,传统的深度学习问题存在两个弊端:
-
与当前人脑智能存在差距,即人脑无需大量样本即可很好的完成分类等任务,而深度神经网络不行;
-
某些情况下产生大量标记样本代价很大,只能产生很小量的标记样本用以学习。
下面我们来看一张图,这张图来自论文《Optimization as a Model for Few-Shot Learning》,左边是训练集一共 5 张图片来自 5 个类,每个类只有1张图片。右边是测试集,理论上可以有任意多个图片用于测试,图中只给出了两张实例。

如果采用传统的深度学习方法,必须能够提供大量 $D_{train}$ 样本图像,比如上图中需要提供大量鸟类、坦克、狗、人、钢琴的图像,才能训练出一个比较好的深度神经网络,使得网络能够以较高的准确率分辨 $D_{test}$ 中的图像。但是如果无法提供大量图像,那么就会出现严重的过拟合(over-fitting)问题,即因为训练的样本太少了,训练出的模型可能在训练集上效果还行,但是在测试集上面会遭遇灾难性的崩塌。或者换句话说,只有给模型提供训练集中的图片时才能正确分类,提供测试集中存在一定差异的相似图片就无法正确分类。因此,FSL问题的关键是解决过拟合 (overfitting) 的问题,一般可以采用元学习的方法来解决FSL问题。
在 FSL 中有一个术语叫做 N-way K-shot,简单的说就是我们需要分类的样本属于 N 个类中一种,但是我们每个类训练集中的样本只有 K 个,即一共只有 N$\cdot$K 个样本的类别是已知的。上图就是一个 5-way 1-shot 的问题。
2. 元学习方法
Meta-Learning
元学习又被称为学会学习(Learn to learn),其核心想法是先学习一个先验知识(prior),这个先验知识对解决 FSL 问题特别有帮助。
以下面这张图为例,为了学习如何从很少的样本中正确的识别分类“狮子”和“碗”(Meta-Test),首先提供一堆其它不同类别的图像(Meta-Train),喂给神经网络进行训练,期望它能够学到区分不同类别的先验知识,然后当提供包含狮子和碗在内的任务时,能够通过少量的微调,快速得到分类准确的模型。
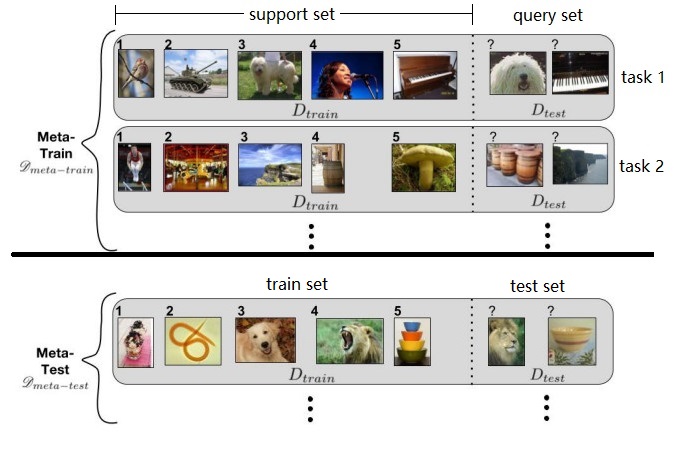
Meta-learning 中有一个术语叫 task ,比如上面图片,是一个 5-way 1-shot 问题,其中每一行 5-way 1-shot 就是一个 task,我们需要先学习很多很多这样的 task,然后再来解决这个新的 task 。最最最重要的一点,这是一个新的 task,这个新的 task 中的类别是之前我们学习过的 task 中没有见过的! 在 Meta-learning 中之前学习的 task 我们称为 meta-train task,我们遇到的新的 task 称为 meta-test task。因为每一个 task 都有自己的训练集和测试集,因此为了不引起混淆,我们把 task 内部的训练集和测试集一般称为 support set 和 query set。
- N-way K-shot:样本包含 N 个类,每个类中的样本只有 K 个,一共有 N$\cdot$K 个样本
- task (meta-task):任务,一个特定的 N-way K-shot 的任务就是一个 task
- meta-train:元训练
- meta-test:元测试
- meta-train task: 元训练阶段的任务
- support set:元训练阶段的训练集
- query set:元训练阶段的测试集
- meta-test:元测试阶段
- train set:元测试阶段的训练集
- test set:元测试阶段的测试集
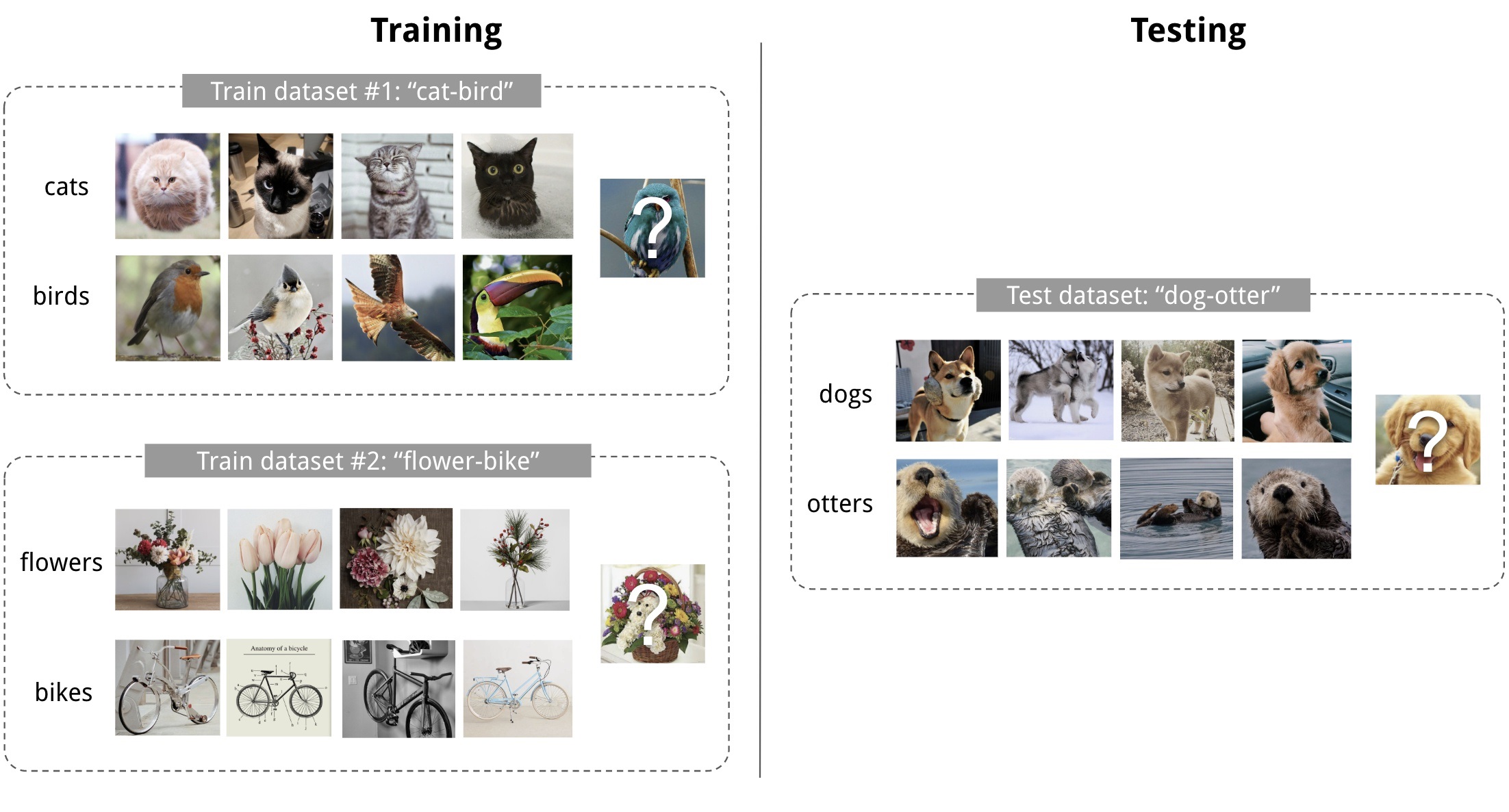
上图展示了 2-way 4-shot 的分类问题。N=2,K=4。希望得到一个模型,能够快速从dogs和otters中进行识别区分。
Few-shot Learning 是 Meta Learning 在监督学习领域的应用。在 meta-training 阶段,将数据集分解为不同的 task,去学习类别变化的情况下模型的泛化能力。在 meta-testing 阶段,面对全新的类别,不需要变动已有的模型,只需要通过一步或者少数几步训练,就可以完成分类。
3. 训练过程
上面已经初步介绍了 Meta-learning 的概念和术语,那么究竟元学习与传统深度学习的差异在哪里,使得元学习能够胜任 FSL 问题呢?
3.1. 深度学习的训练过程
以分类任务为例,首先介绍一下传统深度学习的训练过程,假设我们要训练一个深度神经网络去分类猫和狗。我们需要构造一个数据集,其中包含一堆类,比如“老虎”、“蜥蜴”、“自行车”、“灰机”、以及“猫”和“狗”等等。每个类包含5000个不同的图像,然后划分为两大部分,4000张图像为训练集,1000张图像为测试集:
- 先取一个已标记的图像D1(“Dog no.1”表示第1张狗狗图像),训练网络,正向传播可以计算出一个loss,反向传播可以计算出loss对原始模型参数的梯度;
- 设定一个学习率,可以用上述计算出的梯度的负方向乘以学习率来更新原始模型参数;
- 再取一个已标记图像C5(“Cat no.5”表示第5张猫猫图像),重复上述过程;
- 对训练集中的所有图像都训练完后,拿测试集中的图像来测试,通过模型给出的分类与测试图像的标记做对比,统计准确率。
可以看出,传统的深度学习训练过程,是拿训练集的样本对模型参数进行更新,然后用测试集的样本进行测试。
3.2. 元学习的训练过程
同样以分类任务为例,介绍元学习的训练过程,同样假设我们要训练一个深度神经网络去分类猫和狗,首先我们要构造一个数据集,其中包含一堆类,比如“老虎”、“蜥蜴”、“自行车”、“灰机”、以及“猫”和“狗”等等,但是每类的图像可能只有20个(区别于之前的5000个)。
N-way K-shot 问题的具体训练过程如下:
首先提供一个 few-shot 的数据集,该数据集一般包含了很多的类别,每个类别中又包含了很多个样本(图片)。对训练集进行划分,随机选出若干类别作为训练集,剩余类别作为测试集;
meta-train 阶段:
- 在训练集中随机抽取 N 个类,每个类 K 个样本,为支持集(support set),剩余样本为问询集(query set);
- 在query set 中,剩余样本不一定全都要用到,如下图只用了5类中的2类,每类1个样本;
- support set 和 query set 构成一个 task;
- 每次采样一个 task 进行训练,称为一个 episode;一次性选取若干个task,构成一个batch;
- 一次 meta-train 可以训练多干个 batch(比如10000个);
- 遍历所有 batch 后完成训练。
meta-test 阶段:
- 在测试集中随机抽取 N 个类别,每个类别 K 个样本,作为 train set,剩余样本作为 test set;
- 用 support set 来 fine-tune 模型;
- 用 test set 来测试模型(这里的 test set 就是真正希望模型能够用于分类的数据)。
上述训练过程中,每次训练(episode)都会采样得到不同 task,所以总体来看,训练包含了不同的类别组合,这种机制使得模型学会不同 task 中的共性部分,比如如何提取重要特征及比较样本相似等,忘掉 task 中 task 相关部分。通过这种学习机制学到的模型,在面对新的未见过的 task 时,也能较好地进行分类。
在上述过程中,不同的元学习策略有不同的训练方法,如 MAML、FOMAML、Reptile 等。在后文中详细解读。
4. 参考文献
[1] CaoChengtai. Few-shot learning(少样本学习)和 Meta-learning(元学习)概述.